Self-Attention 机制和代码#
BERT, RoBERTa, ALBERT, SpanBERT, DistilBERT, SesameBERT, SemBERT, SciBERT, BioBERT, MobileBERT, TinyBERT 和 CamemBERT 的共同点是 self-attention 机制. Self-attention 机制不仅是使某种架构被称为"BERT"的原因, 更准确地, 是基于 Tranformer 的架构的共同点. 基于 Transformer 的架构避开了 RNN, 只使用 self-attention 机制来获得输入输出之间的全局依赖关系.
对 self-attention 机制的介绍分为以下几步:
- 准备输入
- 初始化权重
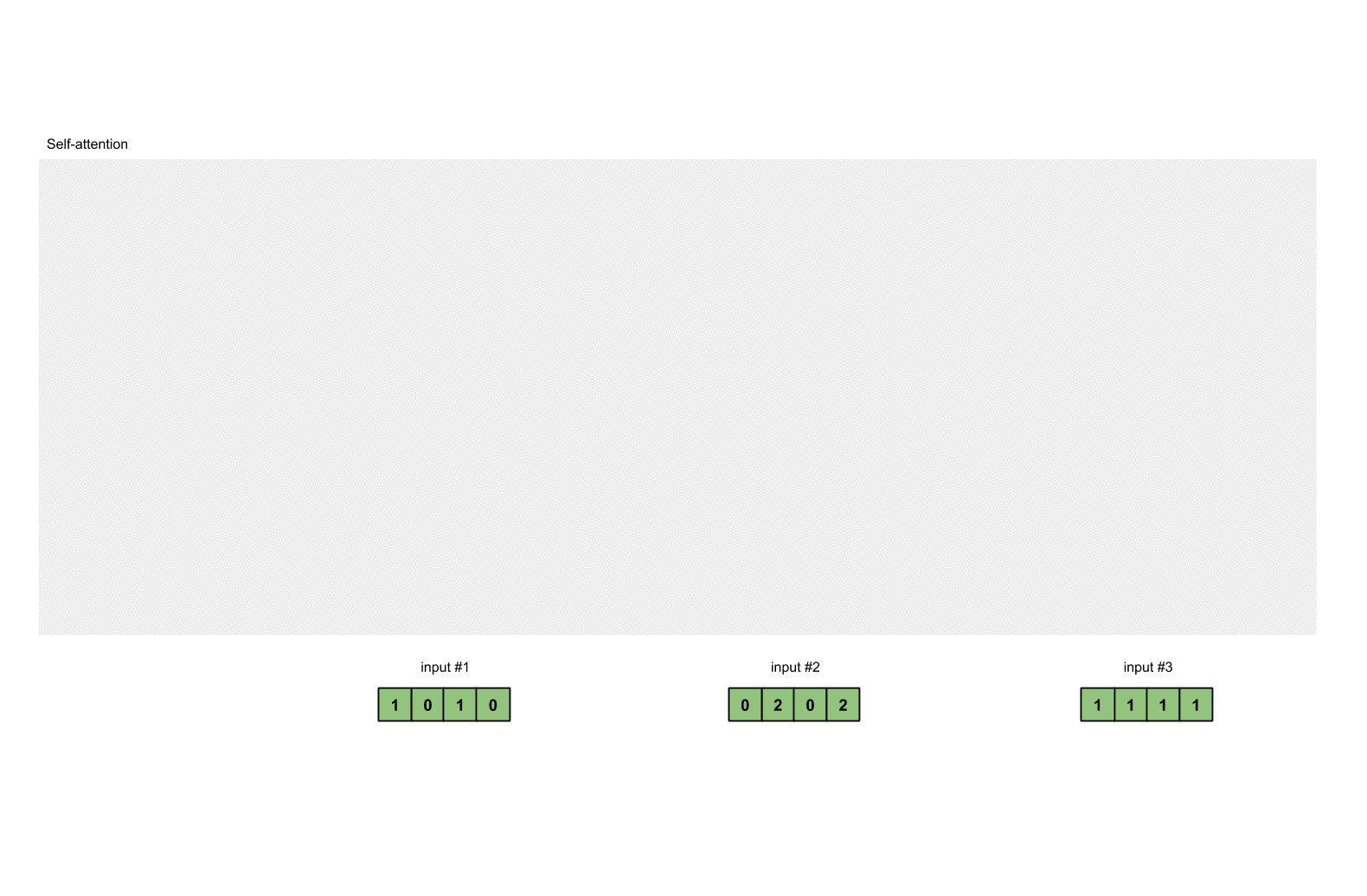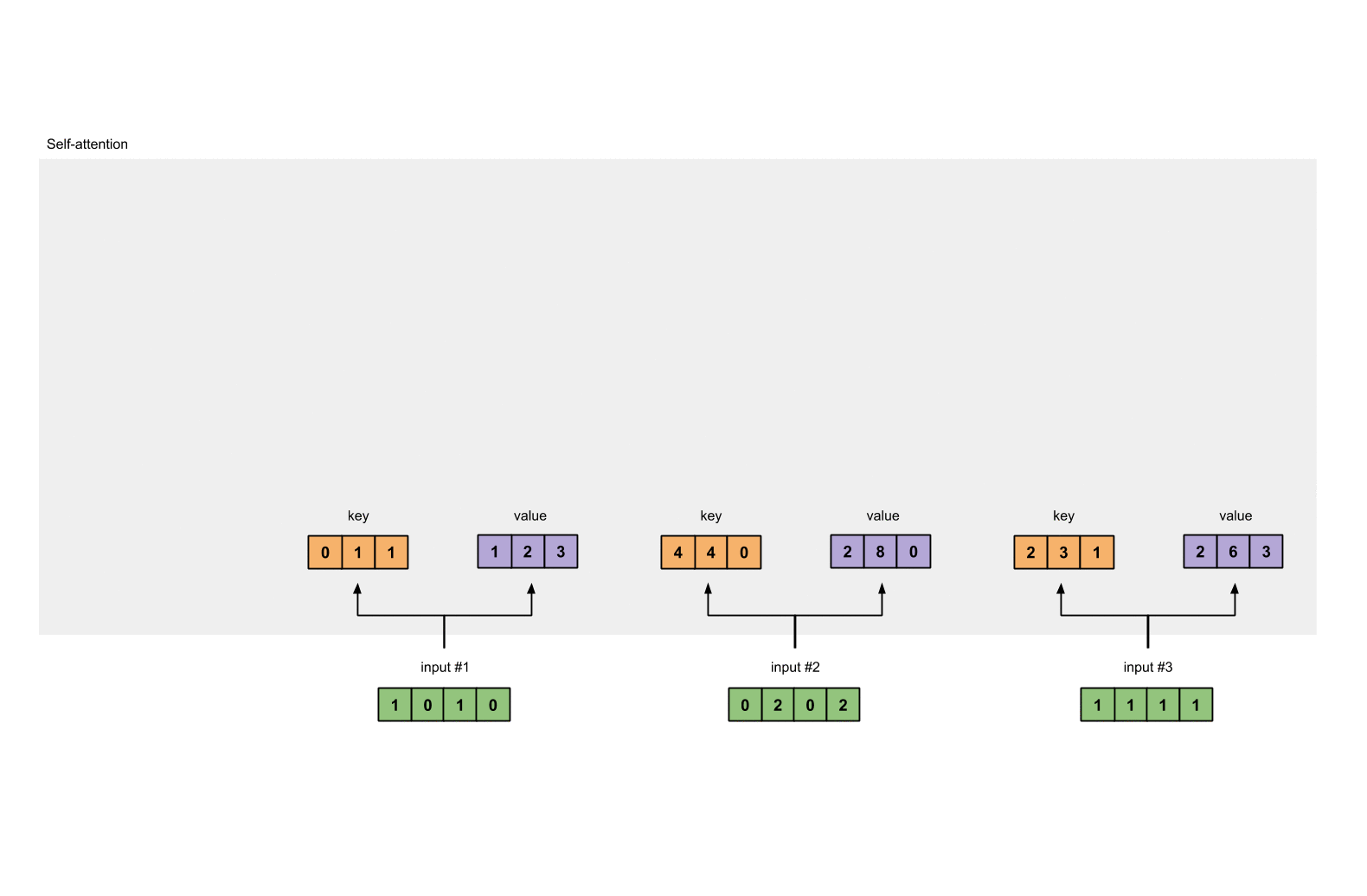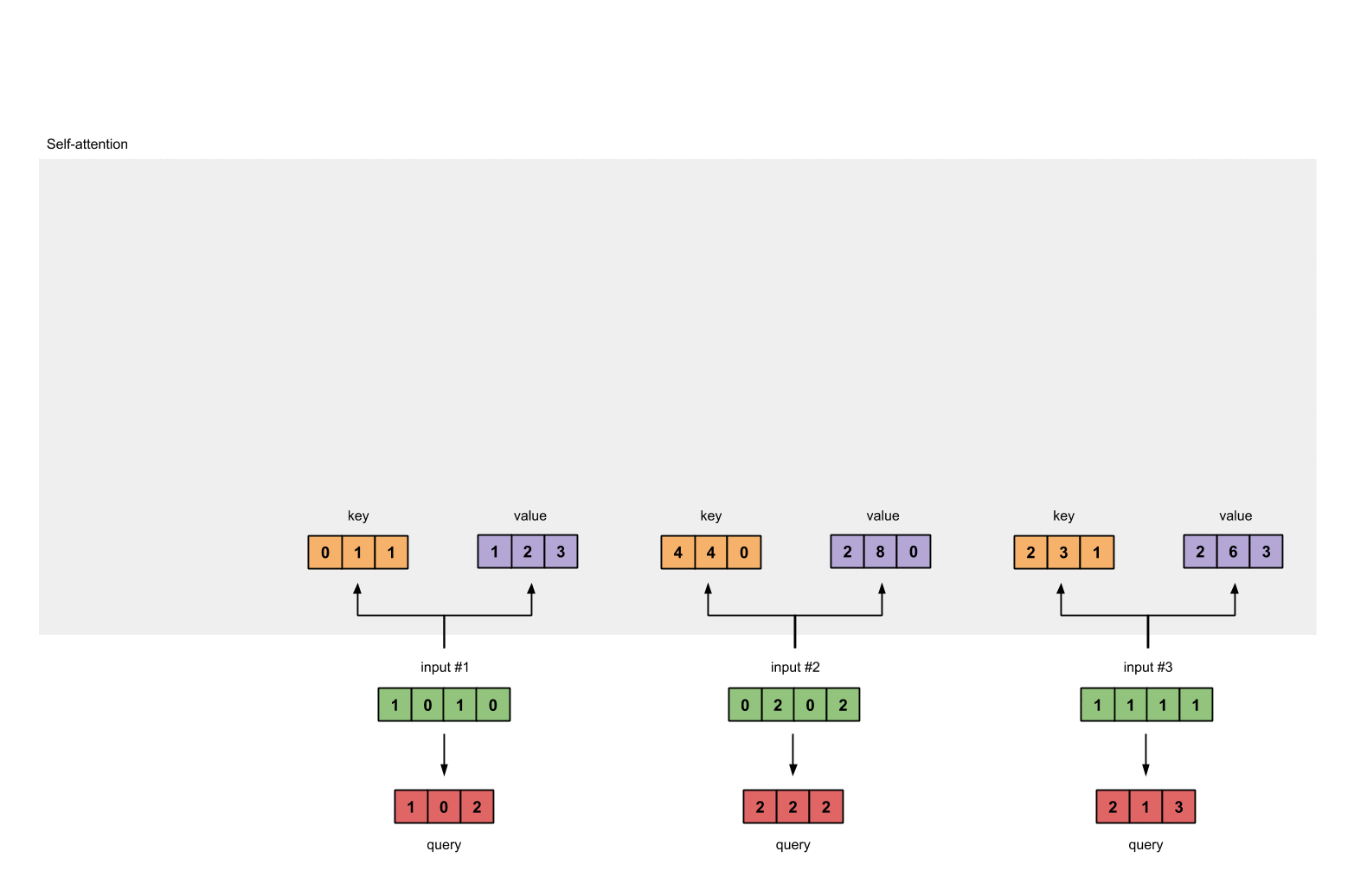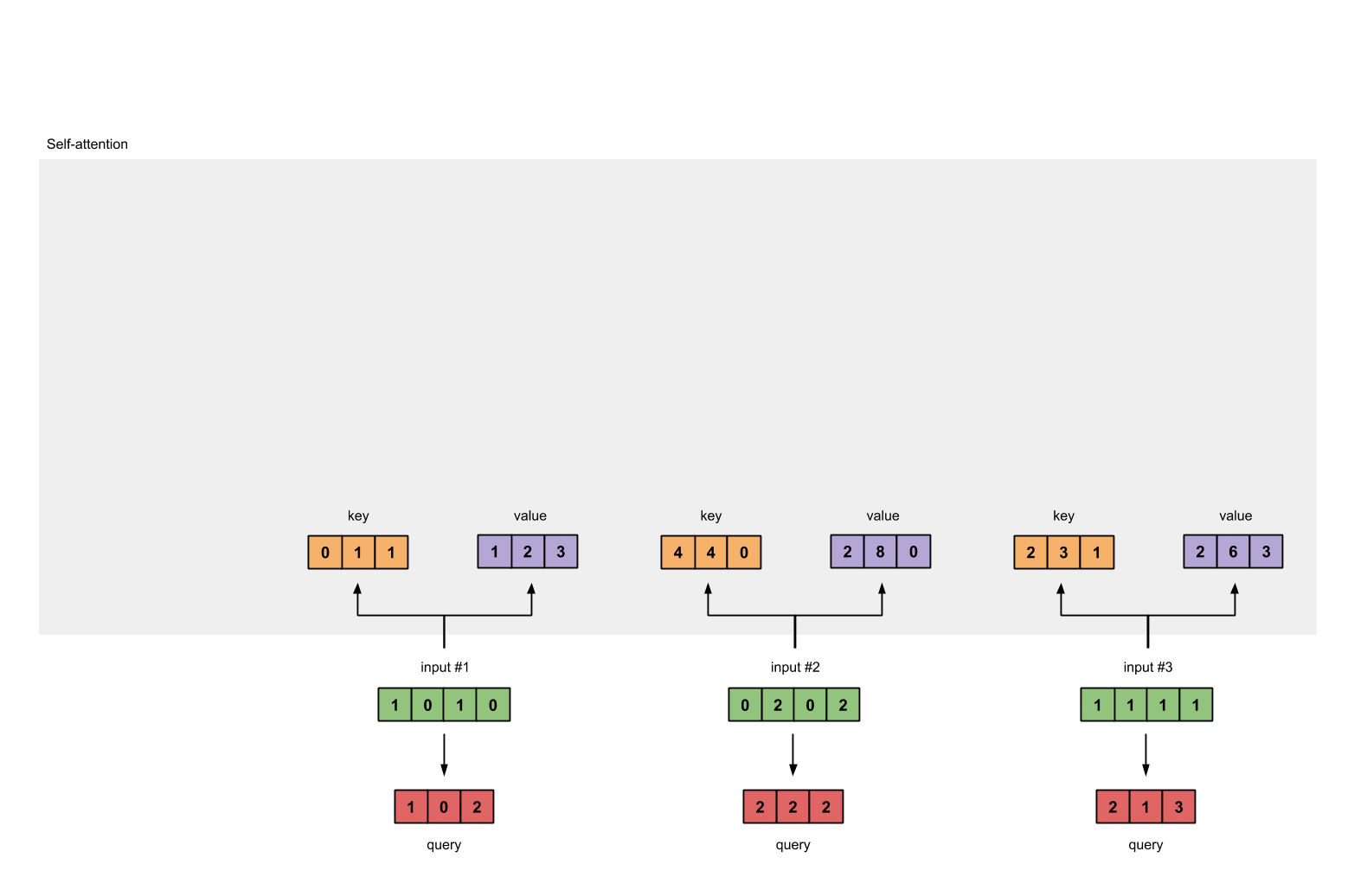
- 分离 key, query 和 value
- 计算对 Input 1 的注意力分数
- 计算 softmax
- 将分数和 value 相乘
- 求 value 的加权和得到 Output 1
- 针对 Input 2, 3 重复步骤 4-7
Step 2: Initialise weights#
每个输入需要有三种表示, 分别被称为 key, query 和 value. 为了得到这三种表示, 每个输入都要分别和三种权重相乘, 得到各自的 key, query 和 value.
这些权重通常是一些较小的数字, 用一些合适的随机分布 (like Gaussian, Xavier and Kaiming distributions) 在训练前进行初始化.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
|
Step 3: Derive key, query and value#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
print(keys)
# tensor([[0., 1., 1.],
# [4., 4., 0.],
# [2., 3., 1.]])
print(querys)
# tensor([[1., 0., 2.],
# [2., 2., 2.],
# [2., 1., 3.]])
print(values)
# tensor([[1., 2., 3.],
# [2., 8., 0.],
# [2., 6., 3.]])
|
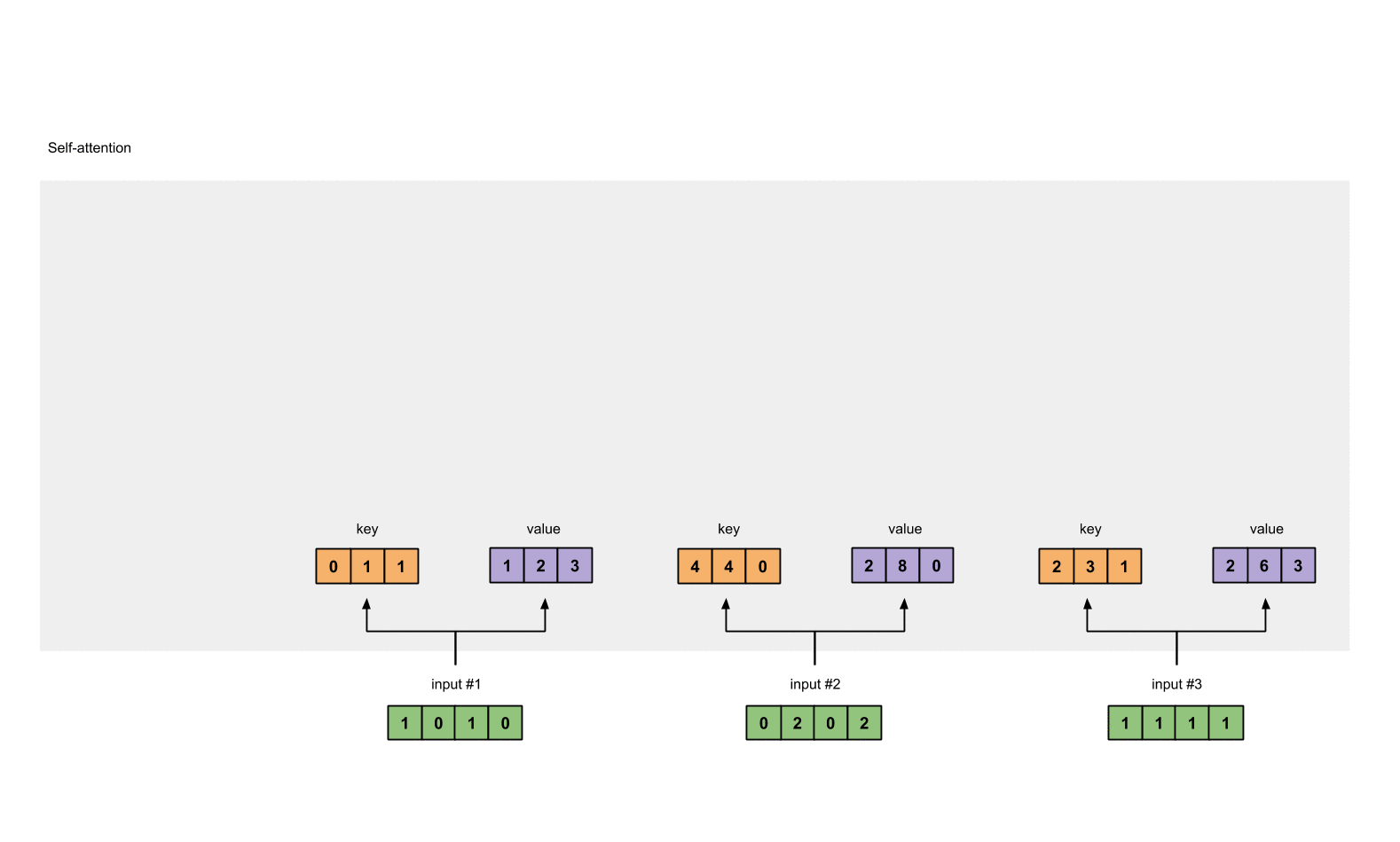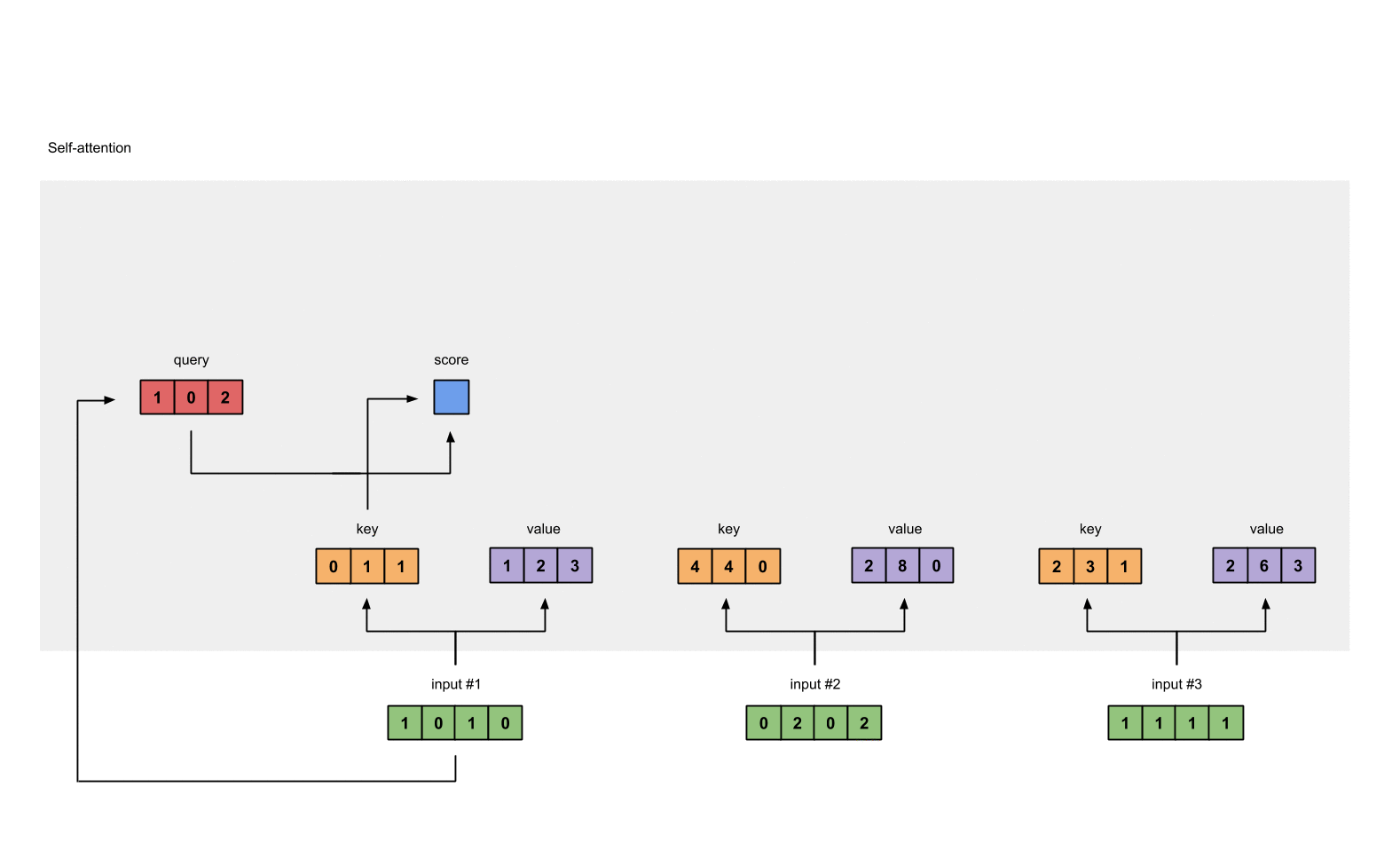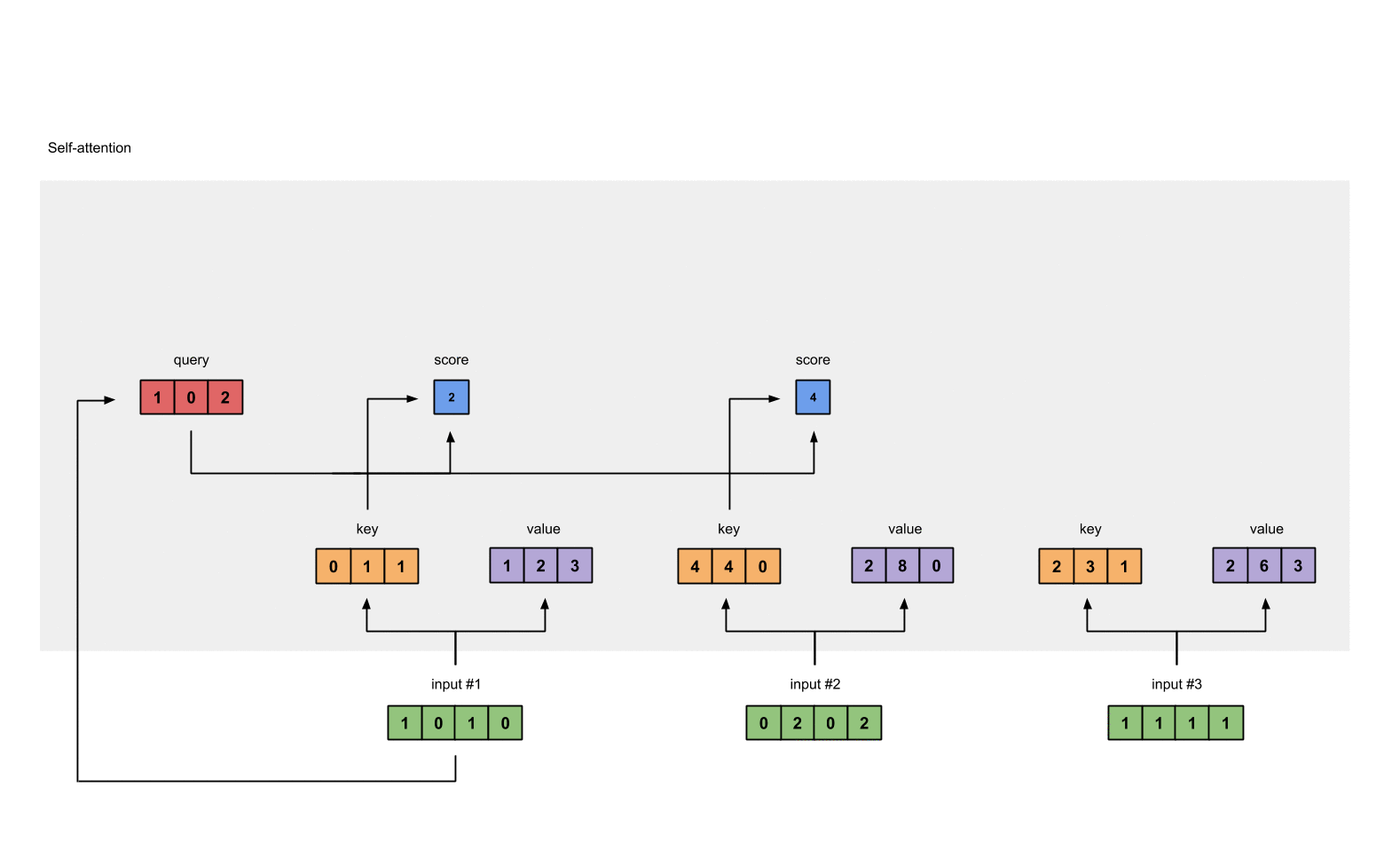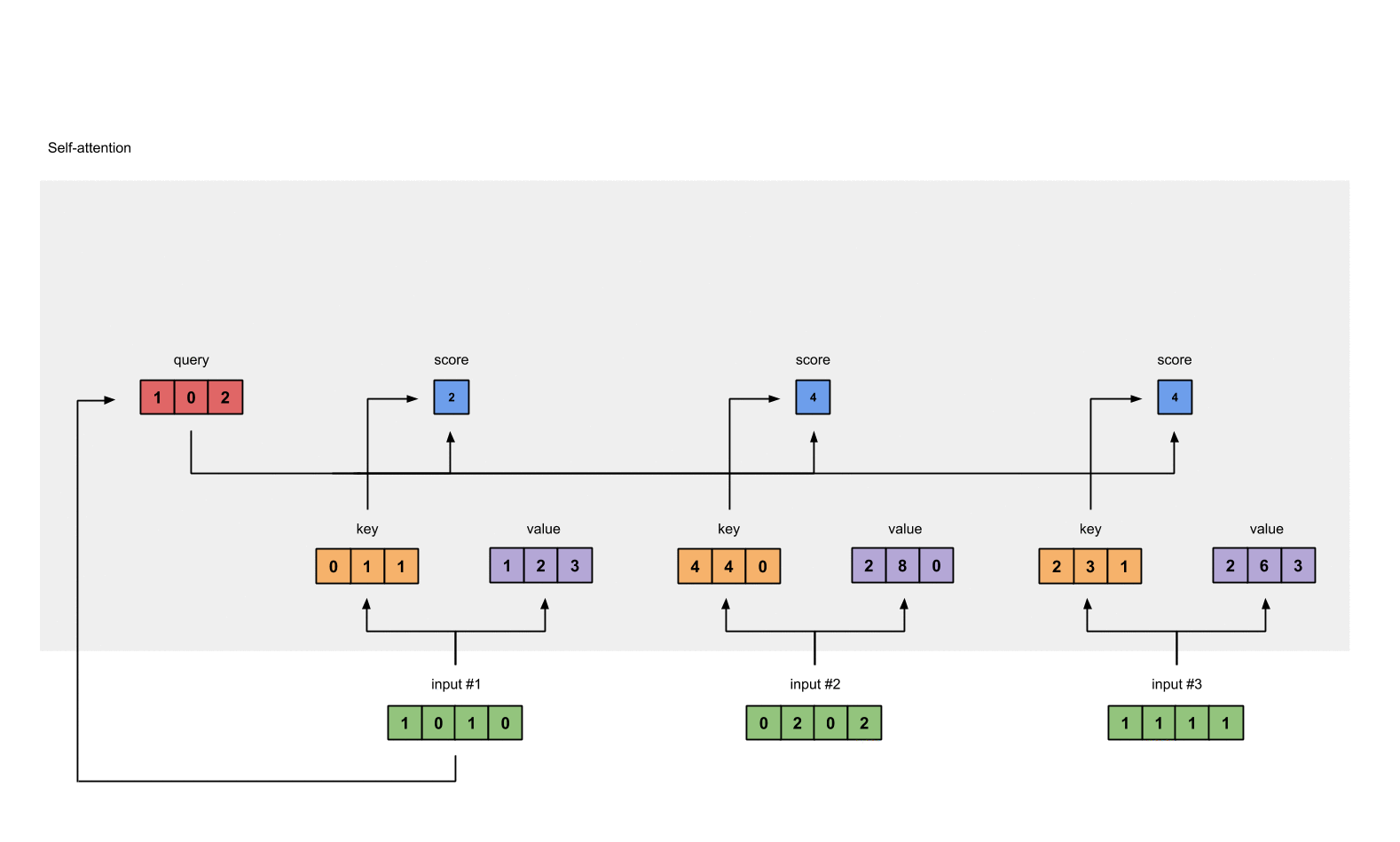
为了得到 Input 1 的分数, 将 Input 1 的 query 和所有输入的 key 做点积 (包括和它自己).
1
2
3
4
5
|
attn_scores = querys @ keys.T
# tensor([[ 2., 4., 4.], # attention scores from Query 1
# [ 4., 16., 12.], # attention scores from Query 2
# [ 4., 12., 10.]]) # attention scores from Query 3
|
Step 5: Calculate softmax#
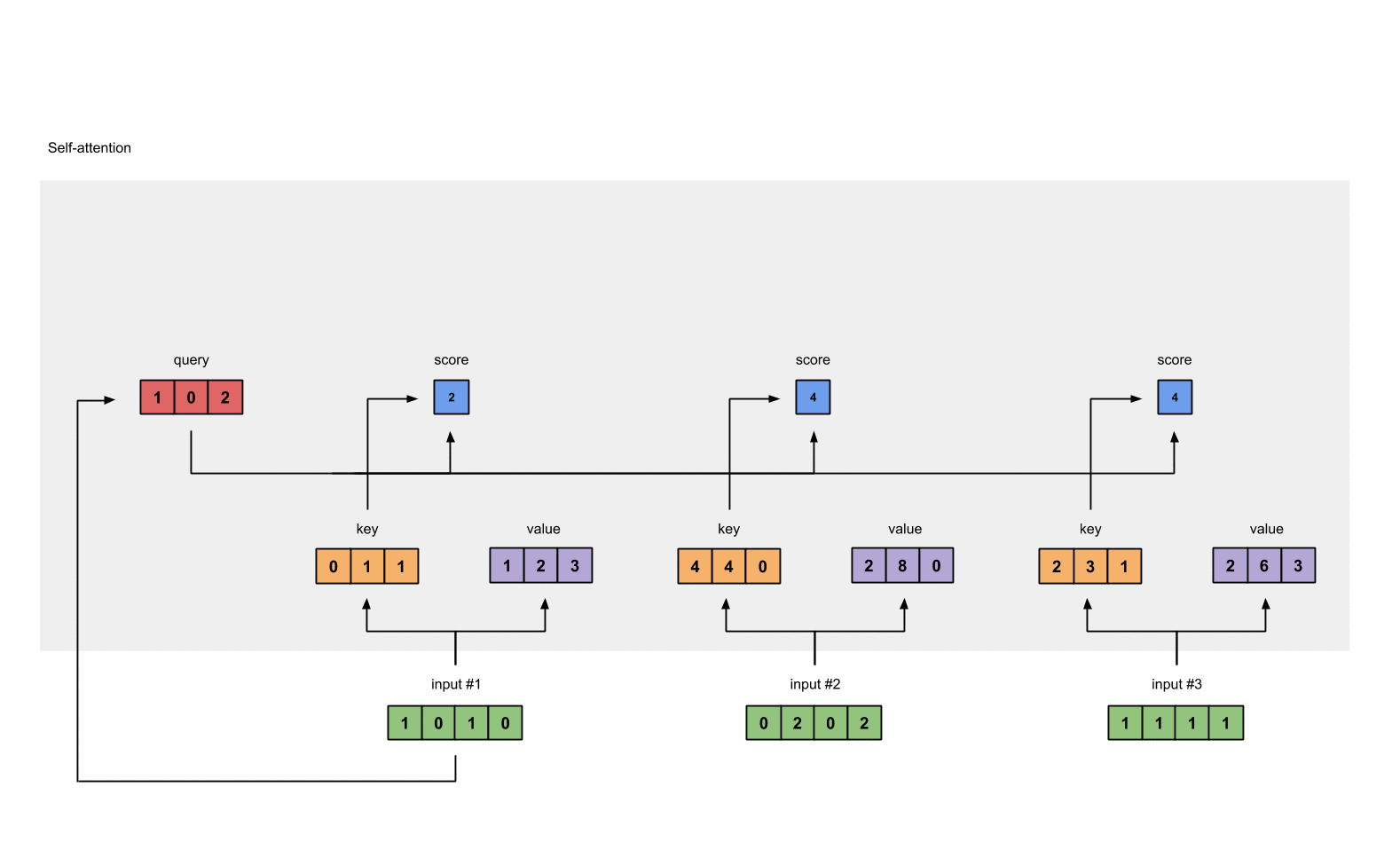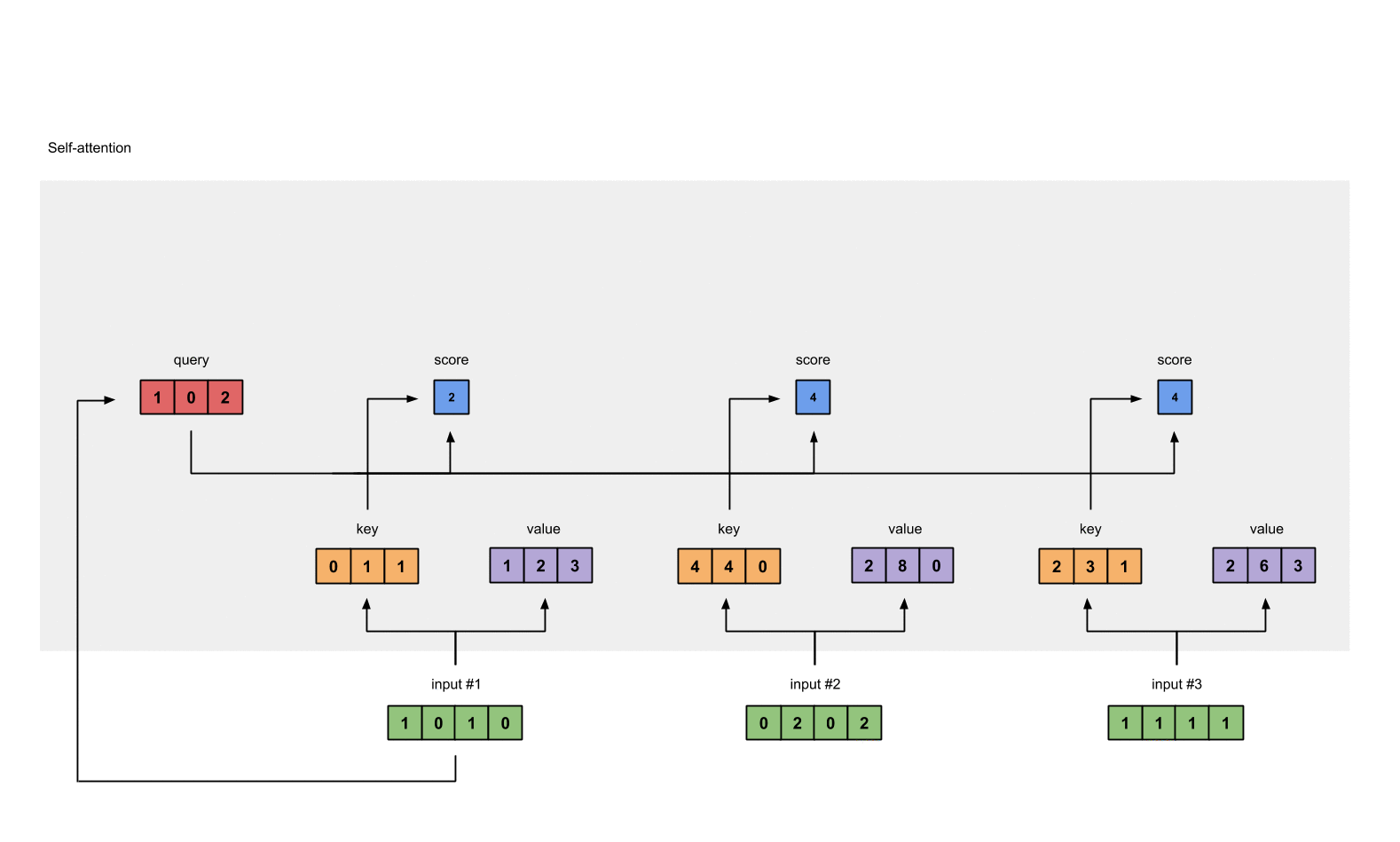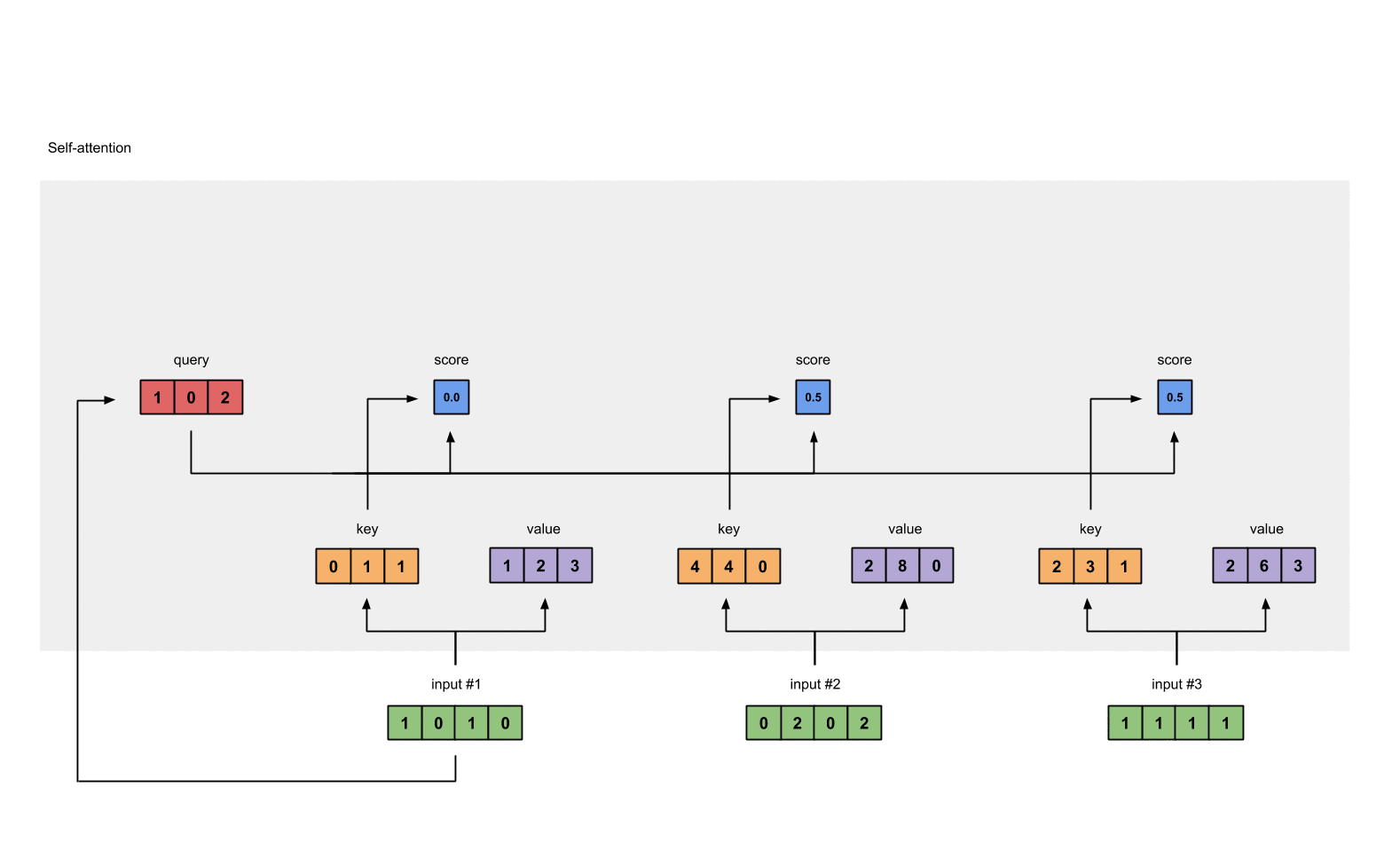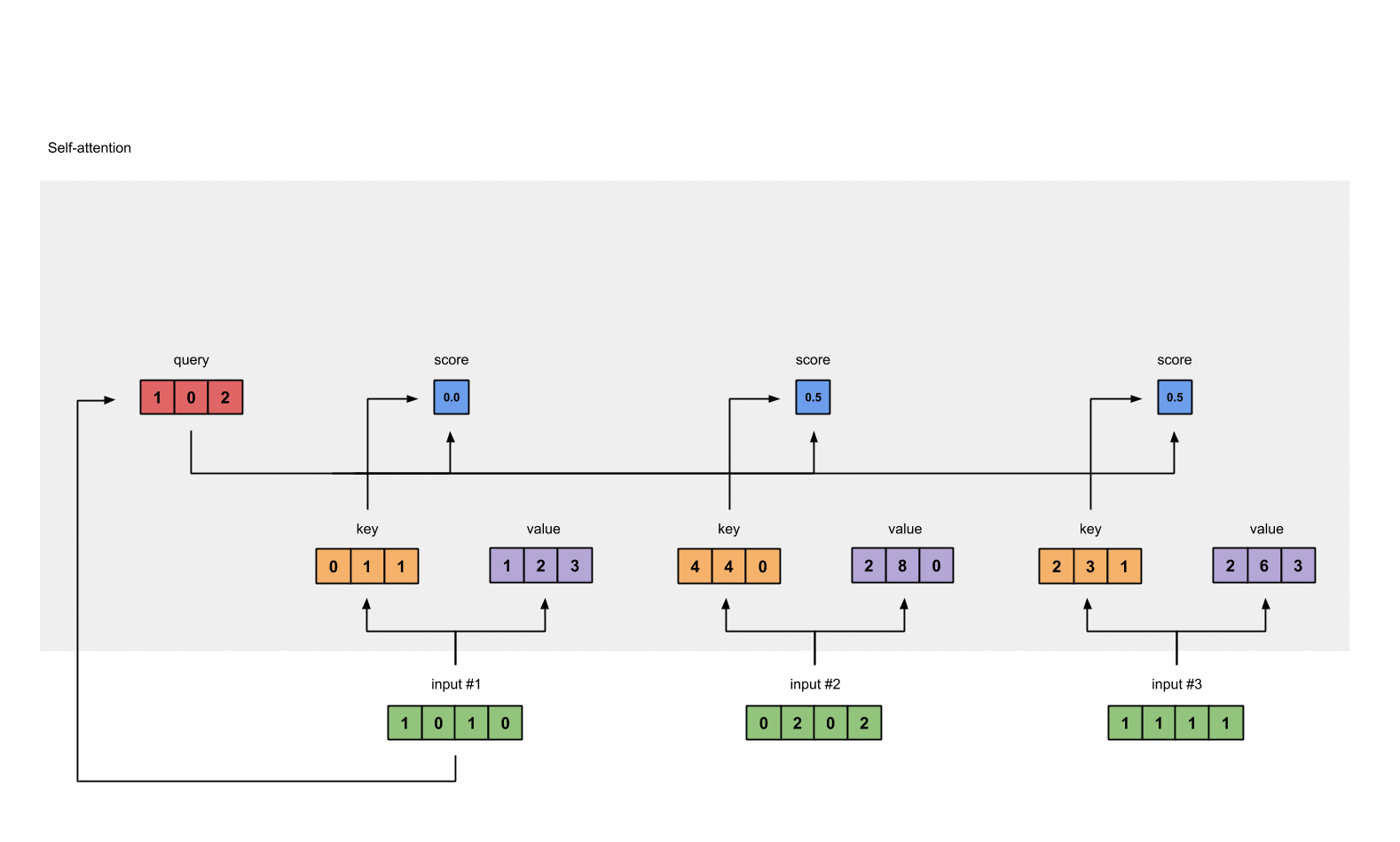
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
|
Step 6: Multiply scores with values#
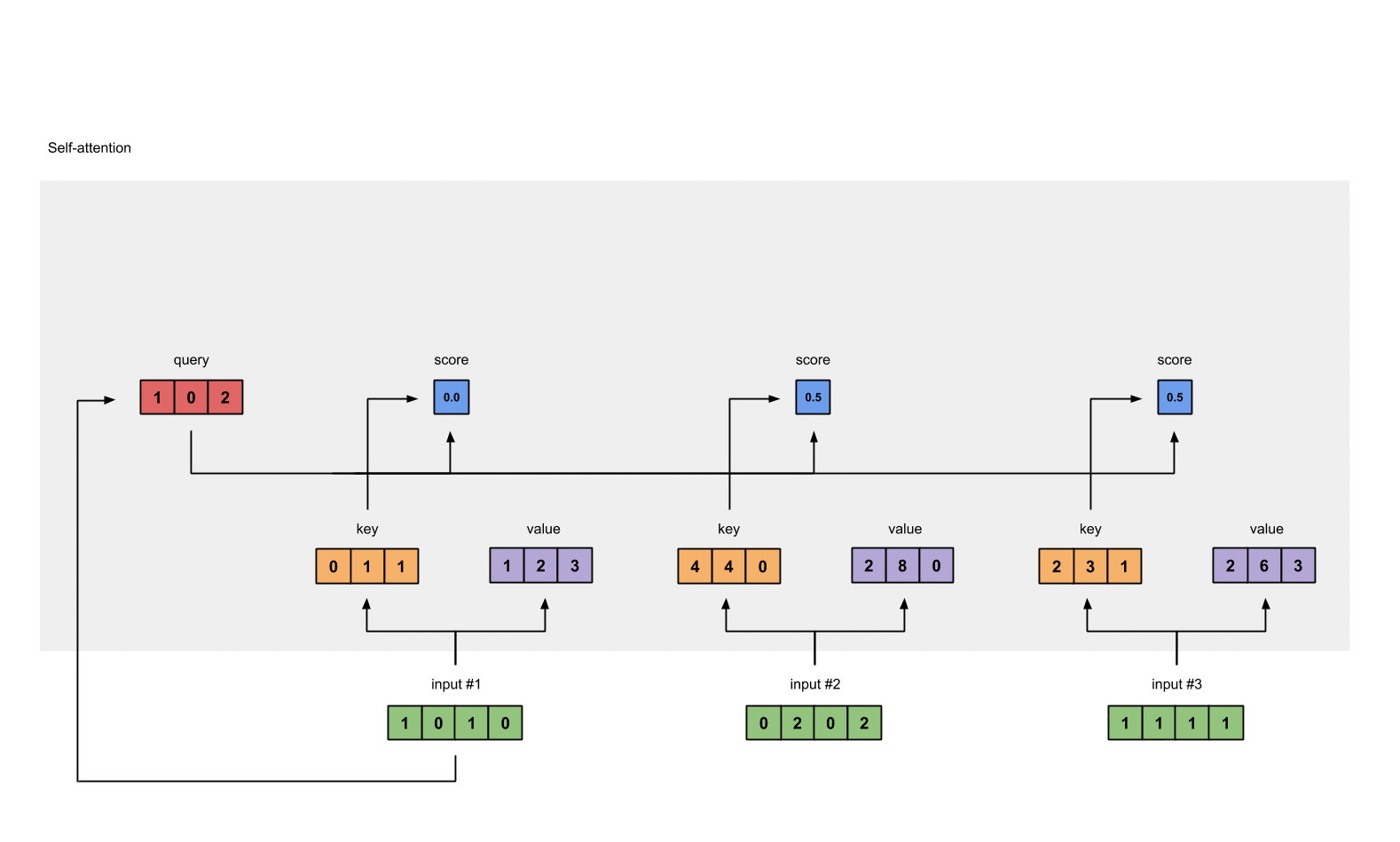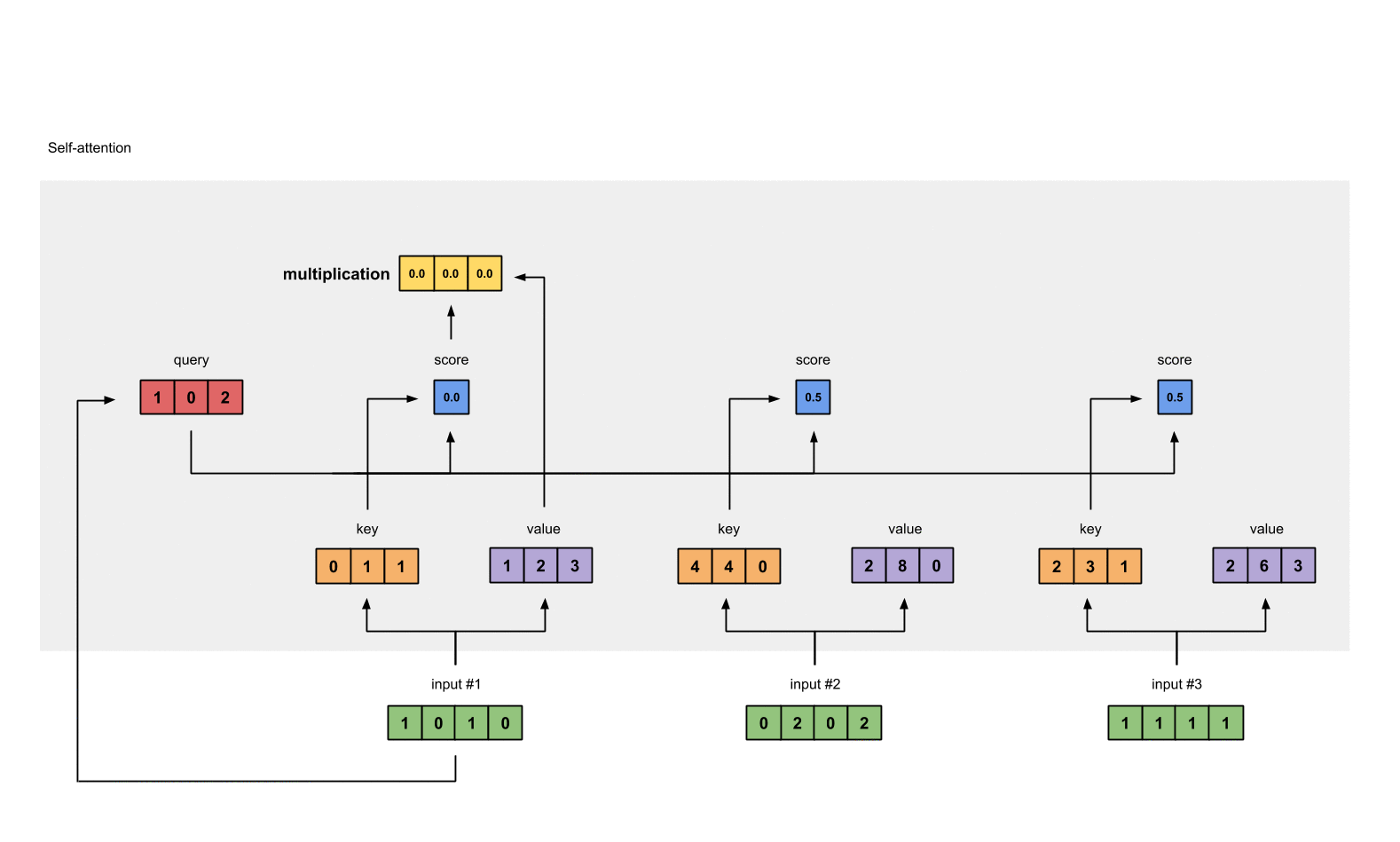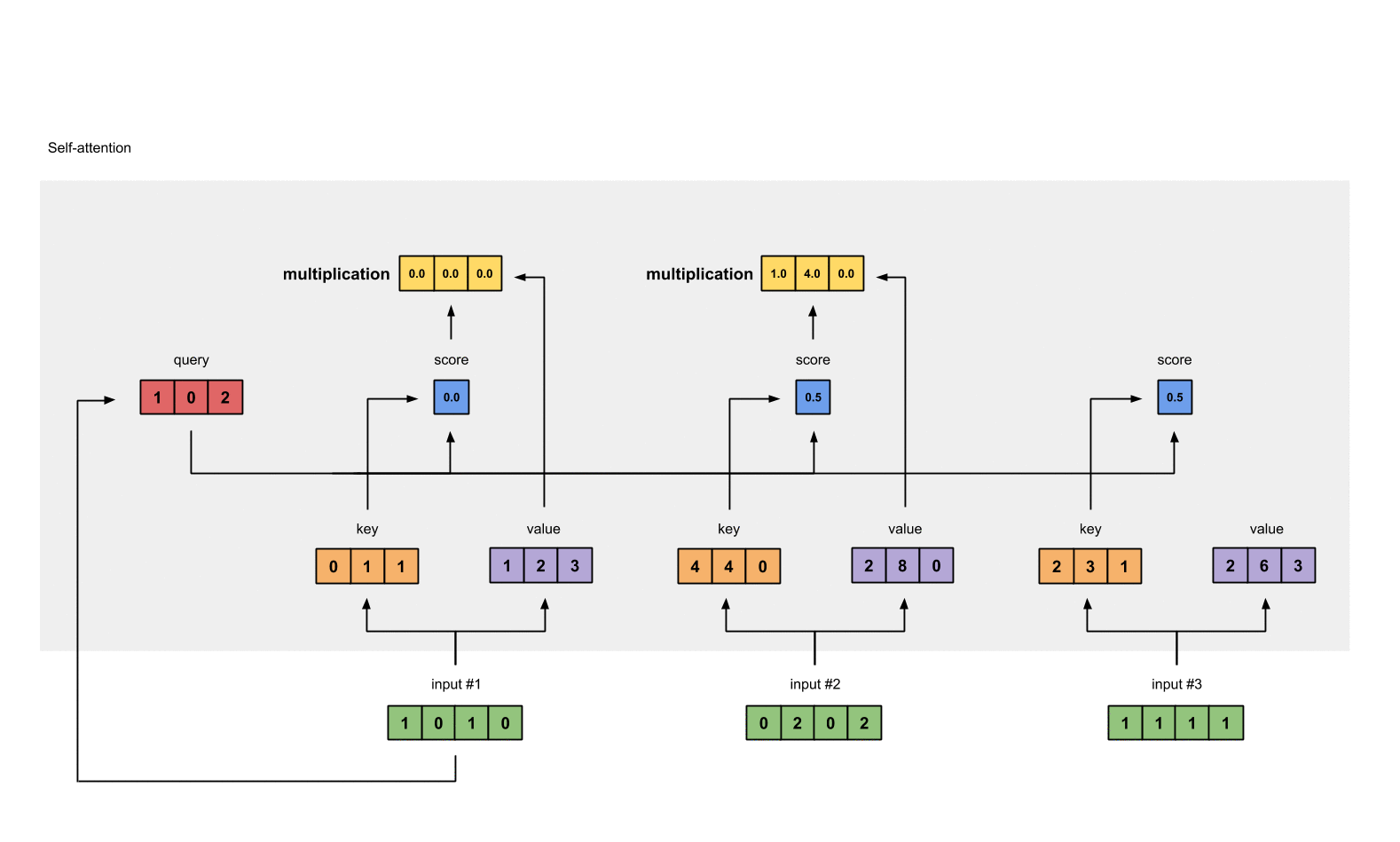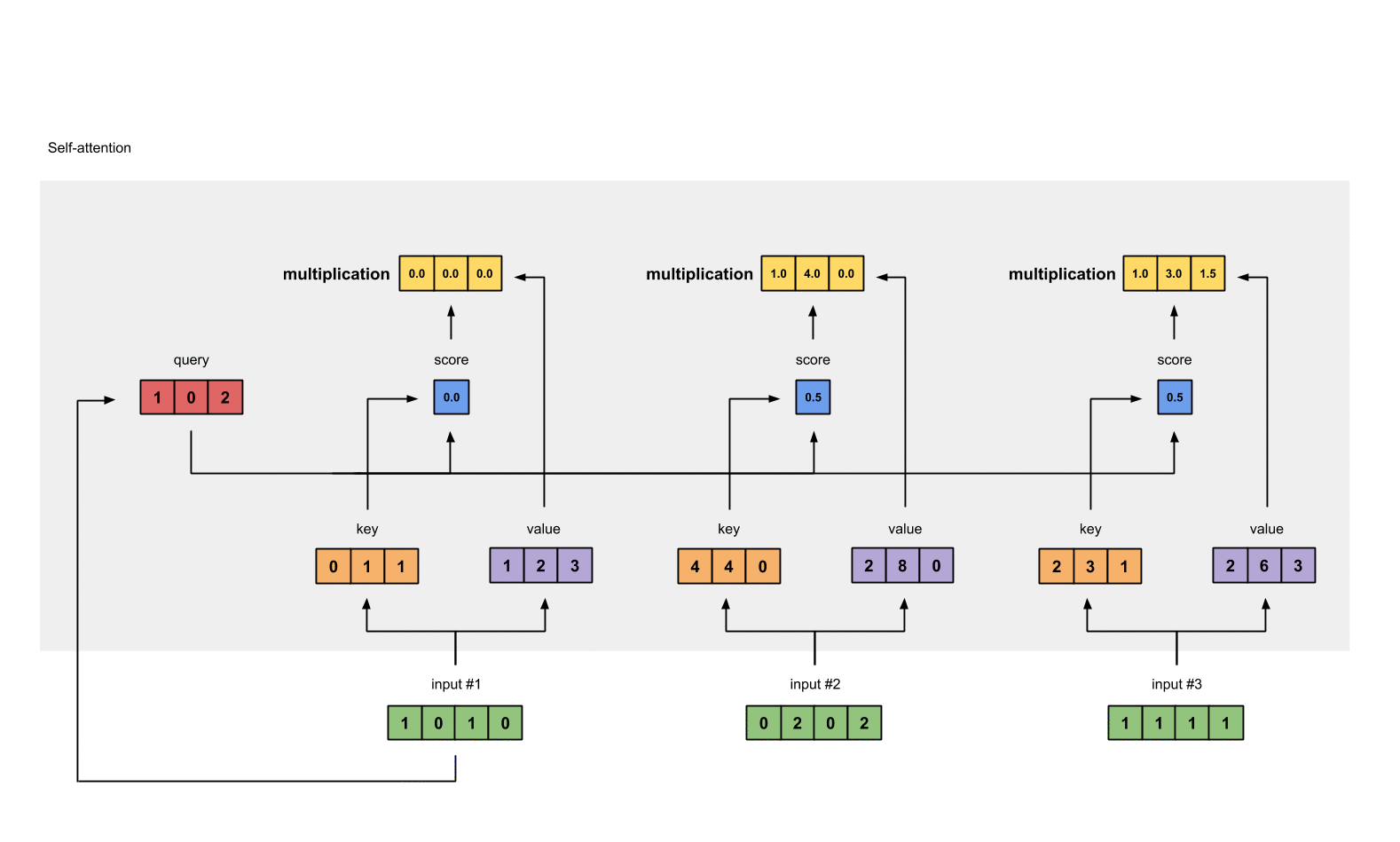
将经过 softmax 的分数作为权重与 value 相乘, 得到加权后的表示.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
# tensor([[[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]],
#
# [[1.0000, 4.0000, 0.0000],
# [2.0000, 8.0000, 0.0000],
# [1.8000, 7.2000, 0.0000]],
#
# [[1.0000, 3.0000, 1.5000],
# [0.0000, 0.0000, 0.0000],
# [0.2000, 0.6000, 0.3000]]])
|
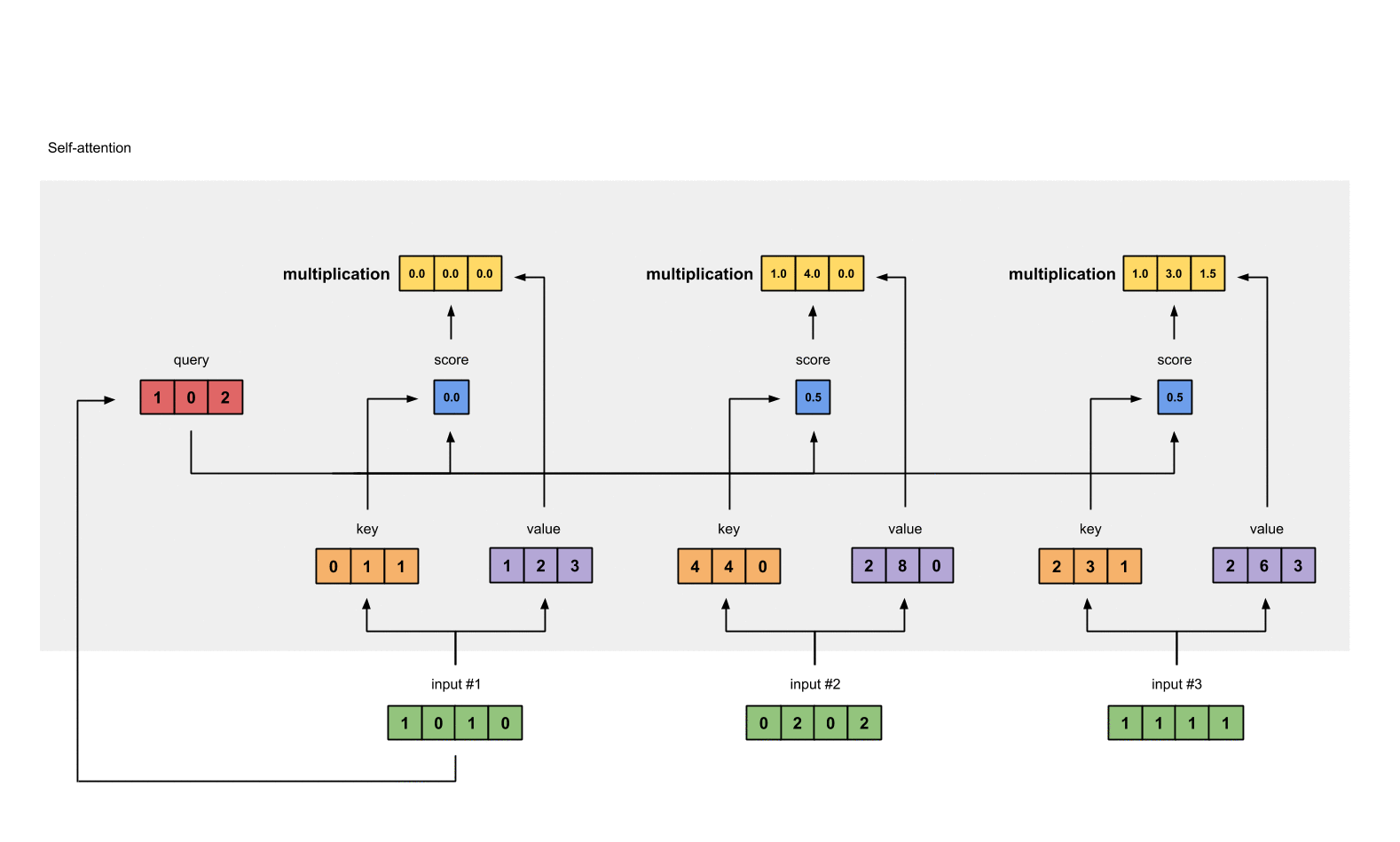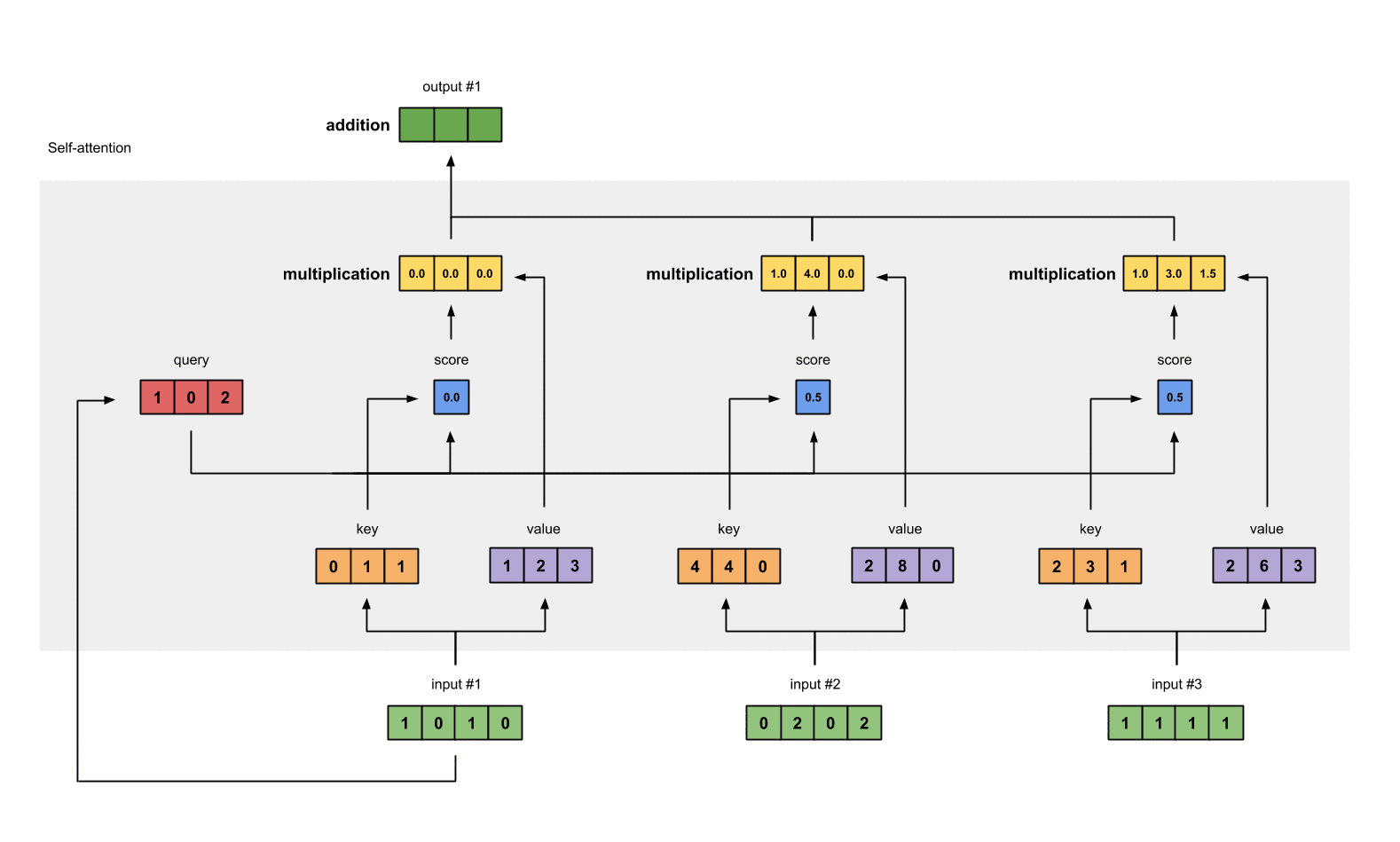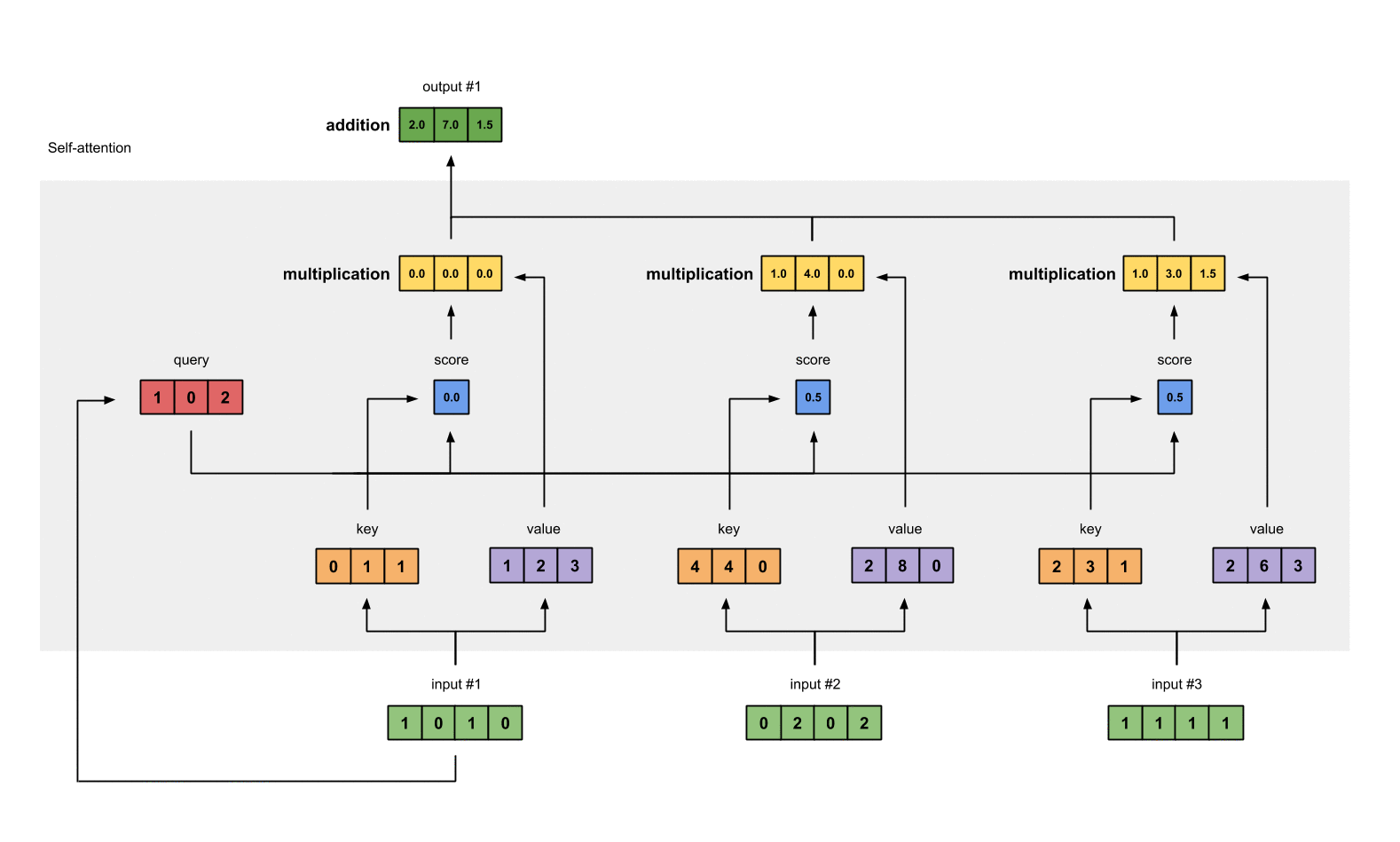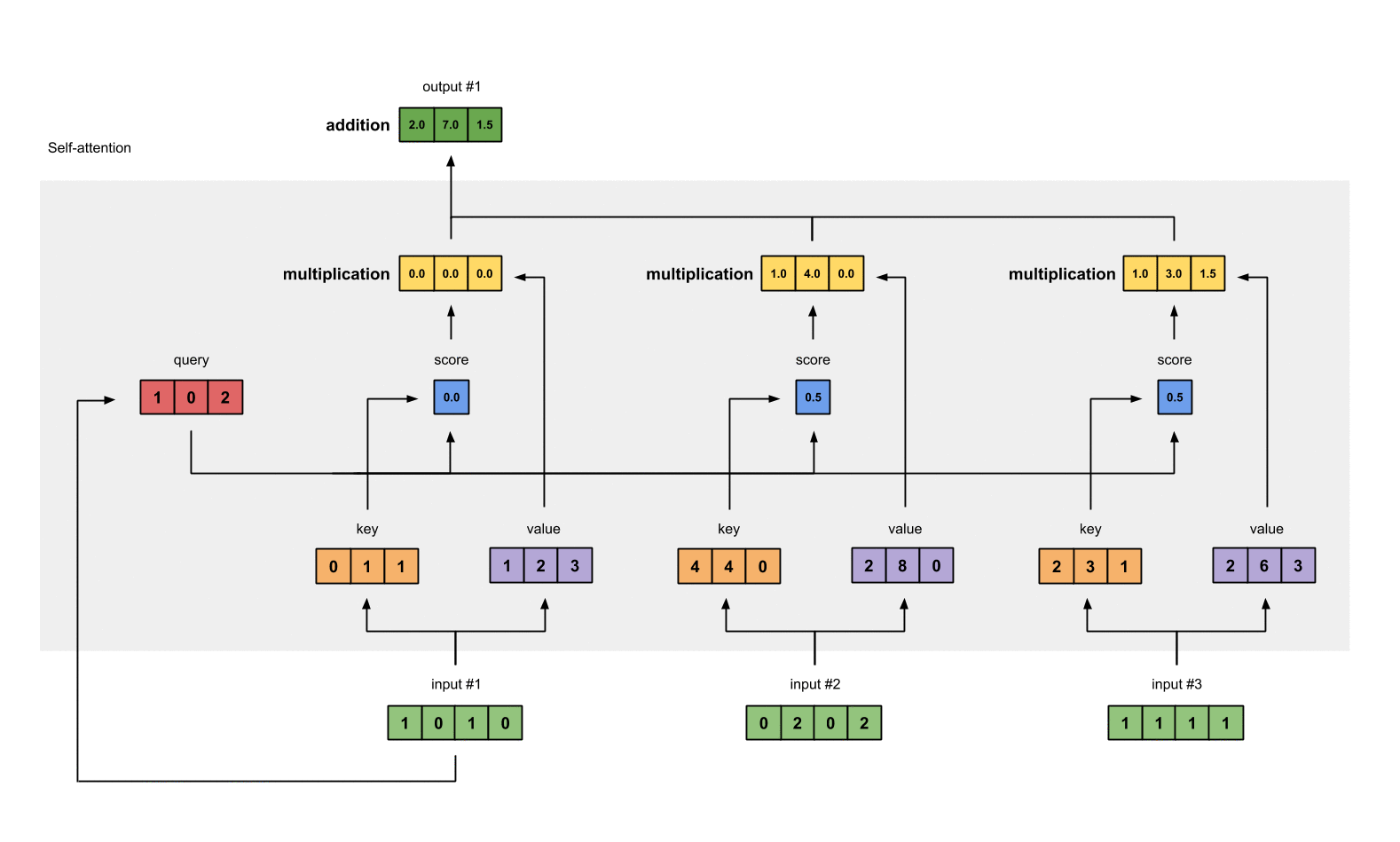
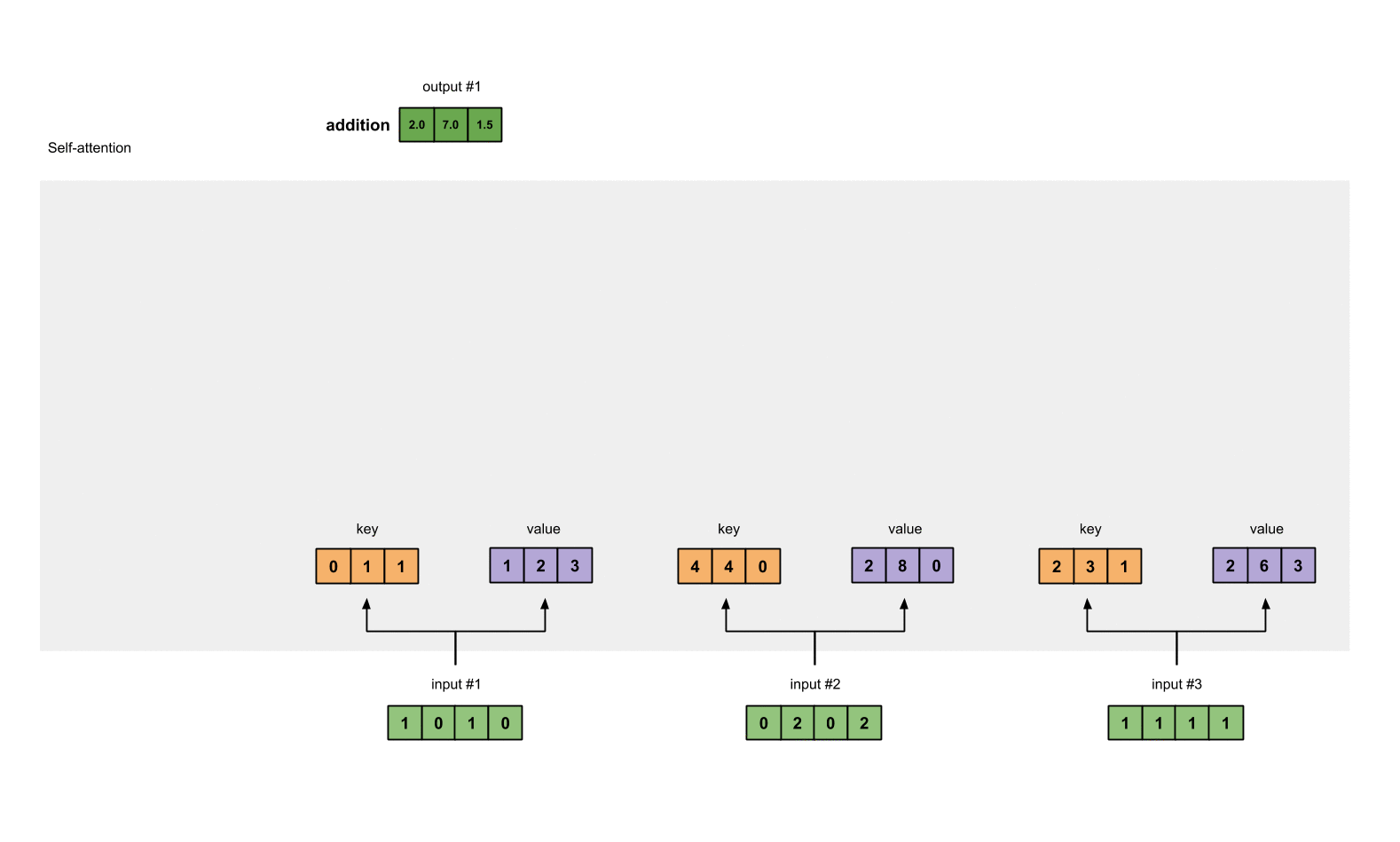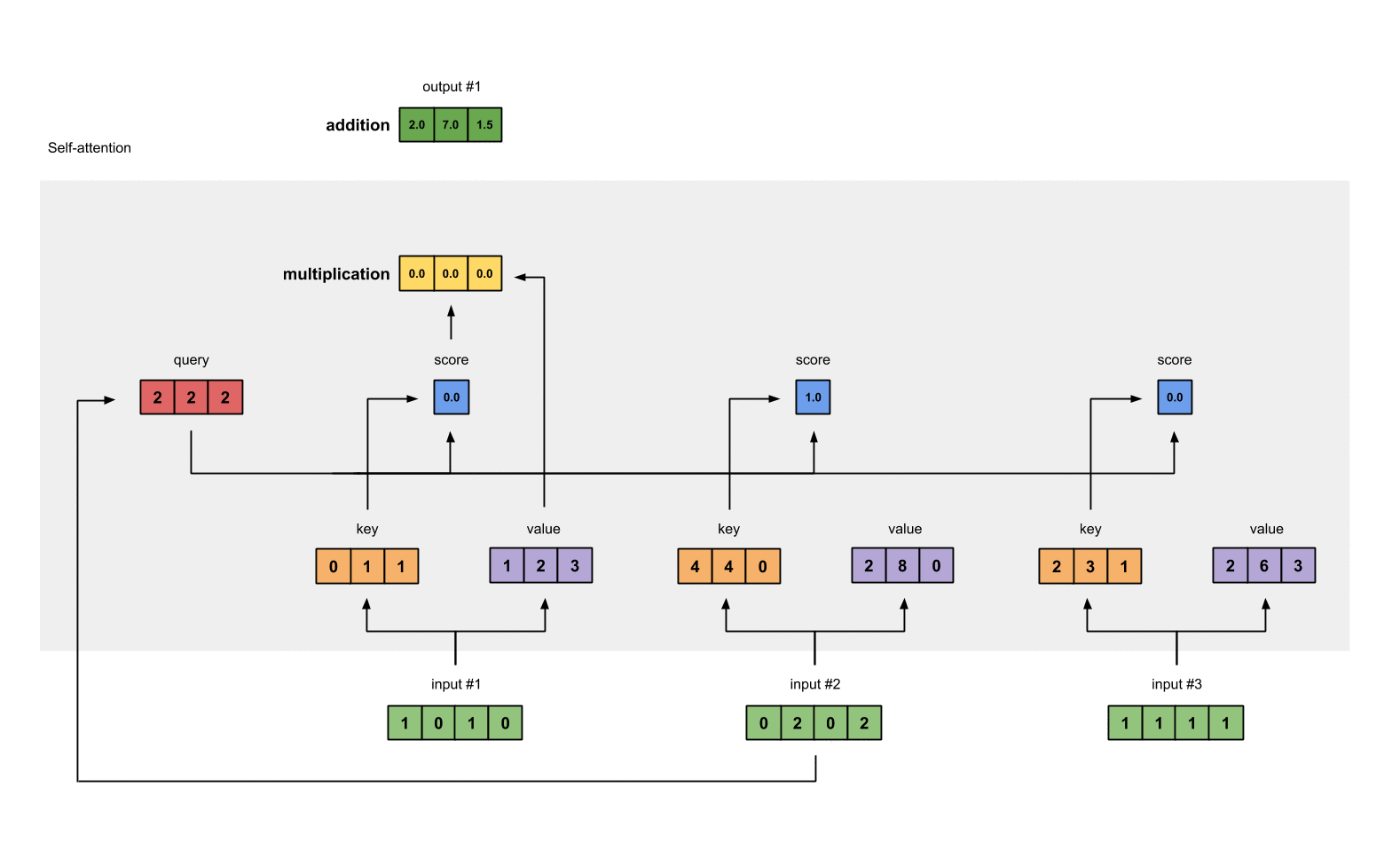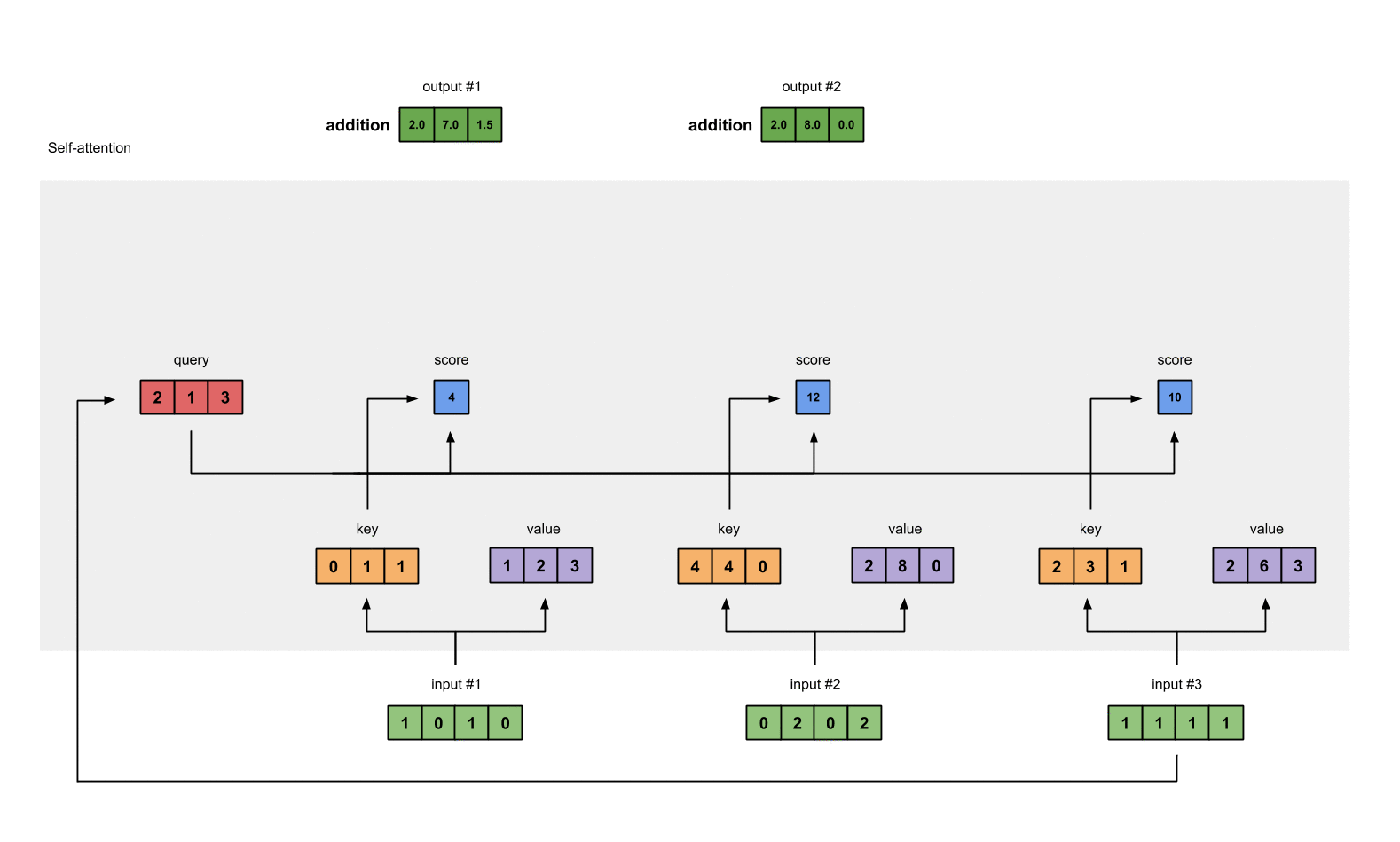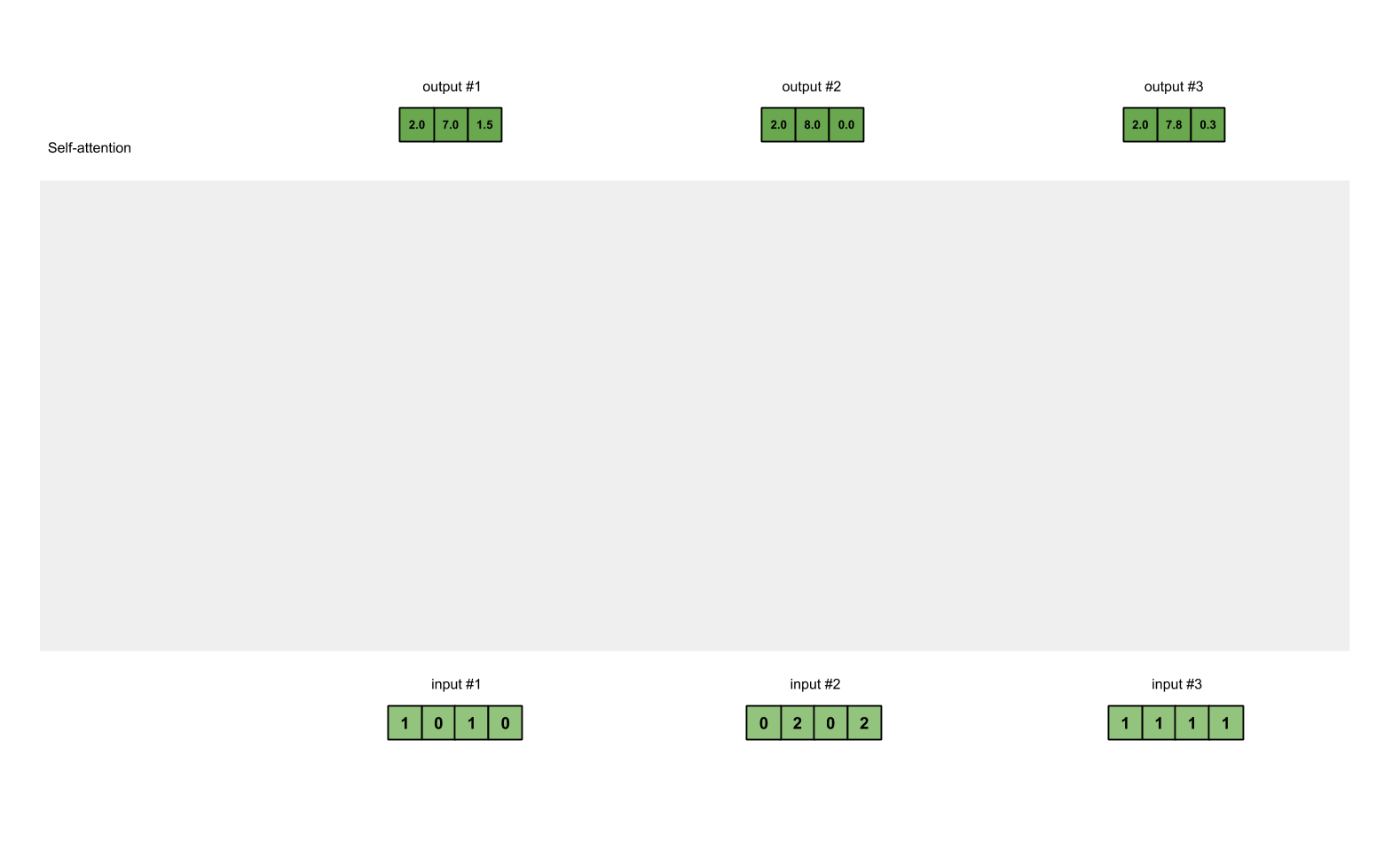
Step 7: Sum weighted values to get Output 1#
将输入的 value 经过 Input 1 所给分数的加权和作为 Ouput 1.
1
2
3
4
5
|
outputs = weighted_values.sum(dim=0)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3
|
在 self-attention 模块内:
输入到 self-attention 模块:
- Embedding module
- Positional encoding
- Truncating
- Masking
加入更多的 self-attention 模块:
Self-attention 模块之间的模块:
- Linear transformation
- LayerNorm