Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks
https://arxiv.org/pdf/2004.05937.pdf
- Learning from Multiple Teacher Networks, KDD 2017
- Efficient knowledge distillation from an ensemble of teachers. Interspeech 2017: 对teacher的logits取加权平均, 加权平均和student的logits计算交叉熵作为损失函数; 另外没有说权是怎么分配的 (提前设置好的).
- A Two-Teacher Framework for Knowledge Distillation. ISNN 2019
- Feature-Level Ensemble Knowledge Distillation for Aggregating Knowledge from Multiple Networks. ECAI 2020
- Adaptive Distillation: Aggregating Knowledge from Multiple Paths for Efficient Distillation: 多教师知识蒸馏中如何整合多教师的知识的问题依然没有得到很好的解决. 不同的教师具有不同的重要性, 且有些教师会对学生的泛化性能产生负面影响. 本文提出了基于多任务学习的自适应方法 (没看懂).
- Ensemble Knowledge Distillation for Learning Improved and Efficient Networks. ECAI 2020
- Knowledge Distillation based Ensemble Learning for Neural Machine Translation. ICLR 2021: 机器翻译方向的文章, 主要提出了新的损失函数.
- A Simple Ensemble Learning Knowledge Distillation. MLIS 2020: 只有一个损失函数 ($\mathcal{L}{CL}+\mathcal{L}{KD}$) (???)
- Stochasticity and Skip Connection Improve Knowledge Transfer. ICLR 2020
- Amalgamating Knowledge towards Comprehensive Classification. AAAI 2019
- Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification. ECCV 2020: 主要用于解决长尾问题, 每个teacher对应几类, 用样本数相近的几类数据去训练的效果会优于从长尾分布的数据中学习.
- Knowledge Amalgamation from Heterogeneous Networks by Common Feature Learning. IJCAI 2019
- Customizing Student Networks From Heterogeneous Teachers via Adaptive Knowledge Amalgamation. CVPR 2019
- Highlight Every Step: Knowledge Distillation via Collaborative Teaching
- Hydra: Preserving Ensemble Diversity for Model Distillation
- Knowledge flow: Improve upon your teachers. ICLR 2019
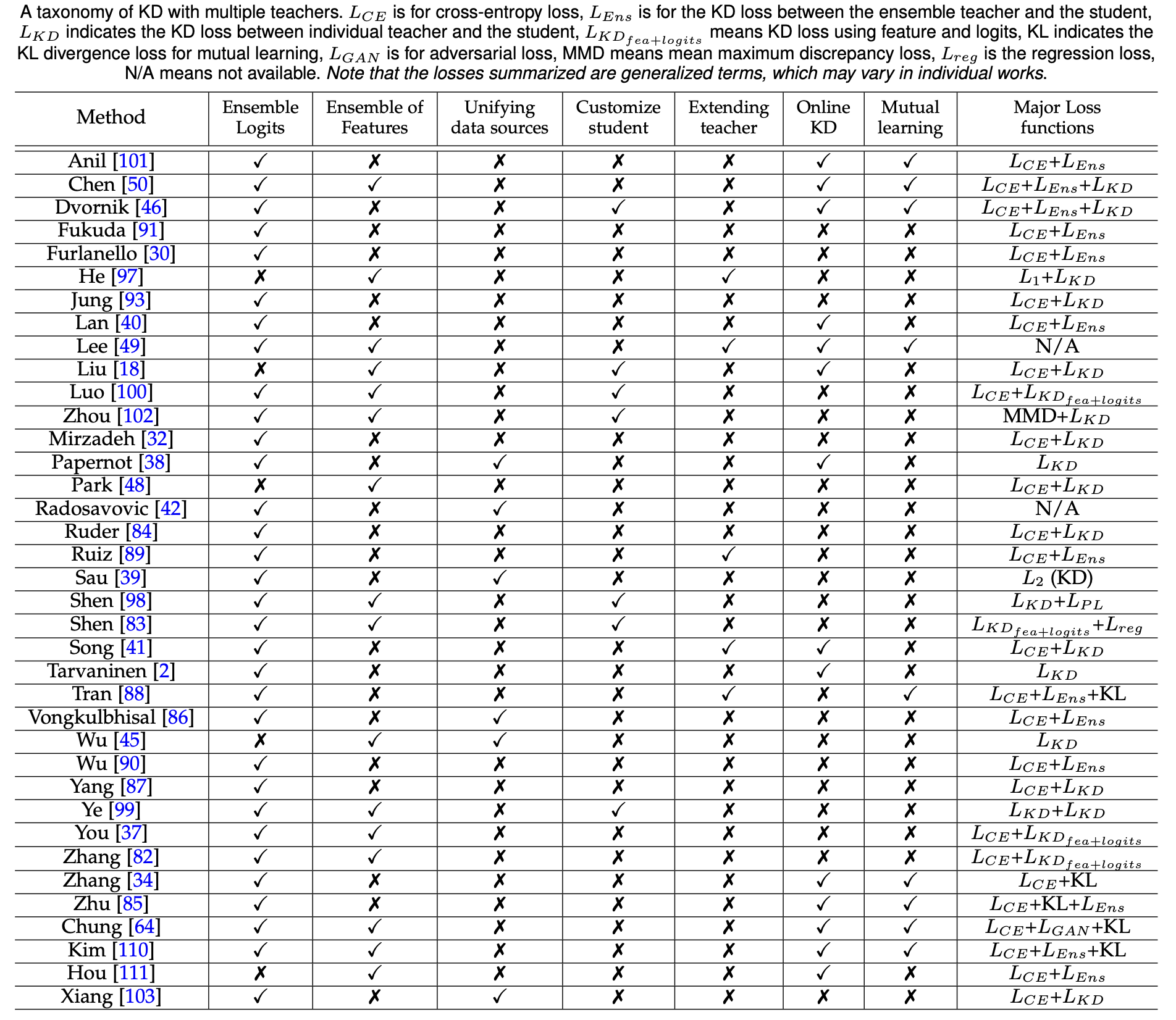
Learning from Multiple Teacher Networks. You, Shan et al. KDD 2017
http://library.usc.edu.ph/ACM/KKD%202017/pdfs/p1285.pdf 这是第一篇提出Multi-teacher KD的文章
- 问题: 如何进行多教师知识蒸馏?
- 方法: 主要改进了loss function, 由三部分组成:
- teachers的softmax输出取平均和student的交叉熵
- 中间层表示的相对相异度 (仅适用于MTKD), 三元组 $(q_i,q_i^+,q_i^-)$, 其中$q_i$是样本$i$在中间层的表示, 偏序关系$q_i^+ > q_i^-$由两者和$q_i$的距离$d$决定, 参数$w_s$决定选取哪层. 在不同teacher中, 输入的三个样本的中间层表示的偏序关系可能不同, 因此用投票法决定正确的偏序关系. 设计和student对应层输出的loss, 以此鼓励student的中间层的表示空间拥有和teacher近似的结构.
- student和groudtruth的交叉熵.
- 实验设置: 基于CIFAR-10, CIFAR-100, MNIST, SVHN的实验
- CIFAR-10, 比较student不同层数和参数量 (11/250K, 11/862K, 13/1.6M, 19/2.5M) 时的表现 (compression rate, acceleration rate and classification accuracy) (和Fitnets比较)
- CIFAR-10, student均为11层, 比较当student的参数为250K和862K时, teacher数量为1, 3, 5时, Teacher, RDL, FitNets, KD和他们的准确率
- CIFAR-10, CIFAR-100, 比较不同方法 (Teacher (5层), FitNets, KD, Maxout Networks, Network in Network, Deeply-Supervised Networks和此方法 (19层)) 在两个数据集上的准确率
- MNIST, 比较不同方法 (Teacher (4层), FitNets, KD, Maxout Networks, Network in Network, Deeply-Supervised Networks和此方法 (7层)) 的准确率
- SVHN, 比较不同方法 (Teacher (5层), FitNets, KD, Maxout Networks, Network in Network, Deeply-Supervised Networks和此方法 (19层)) 的准确率
- @inproceedings{you2017learning, author={You, Shan and Xu, Chang and Xu, Chao and Tao, Dacheng}, booktitle={Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining}, title={Learning from multiple teacher networks}, pages={1285–1294}, year={2017} }
A Two-Teacher Framework for Knowledge Distillation. ISNN 2019
https://link.springer.com/chapter/10.1007%2F978-3-030-22796-8_7 (找不到pdf, 只有网页版)
- 问题: single-teacher KD不行.
- 方法: 该框架由两个以不同策略训练的教师网络组成, 一个被严格地训练以指导学生网络学习复杂的特征 (loss为每一层表示的差), 另一个指导学生网络学习基于学到的特征进行的决策 (loss为教师和学生logits的交叉熵).
- 其中用到了adversarial learning的方法, 用一个discriminator分辨教师和学生的表示.
- 实验设置: 实验做得又少又拉, 也没跟single-teacher比, 就不写了.
- @InProceedings{10.1007/978-3-030-22796-8_7, title = {A Two-Teacher Framework for Knowledge Distillation}, author = {Chen, Xingjian, Su Jianbo, Zhang Jun", booktitle = {Advances in Neural Networks – ISNN 2019}, pages = {58–66}, year = {2019} }
Feature-Level Ensemble Knowledge Distillation for Aggregating Knowledge from Multiple Networks. ECAI 2020
https://ecai2020.eu/papers/405_paper.pdf (这篇和上次的FEED是同一篇)
- 问题: 多教师知识蒸馏在使用基于feature-map的蒸馏任务中不方便.
- 方法: 加入一些非线性转换层. loss function由两部分组成: student和groudtruth的交叉熵; student的feature经过n种非线性转换并归一化, 分别和teacher的feature (归一化后) 做差并求一范式.
- 实验设置: 数据集: CIFAR-100; 选取模型: student – ResNet-56, ResNet-110, WRN28-10, ResNext29-16x64d; 没说teacher是谁.
- @article{Park2019FEEDFE, title={FEED: Feature-level Ensemble for Knowledge Distillation}, author={Seonguk Park and Nojun Kwak}, journal={ECAI}, year={2020} }
Ensemble Knowledge Distillation for Learning Improved and Efficient Networks. ECAI 2020
- 问题: 由CNN组成的集成模型在模型泛化方面表现出显着改进,但代价是计算量大和内存需求大. (机翻的, 摘要提出来的问题貌似和他后面做的事没啥关系, 且这篇和上次看的倒数第二篇结构一样)
- 方法: 学生由多个branch组成, 每个branch和teacher一一对应, loss由三部分组成: teacher (多teacher输出相加) 和groundtruth的交叉熵, student (多branch的输出相加) 和groungtruth的交叉熵, teacher和student对应branch表示的KL散度和MSE.
- 结构:
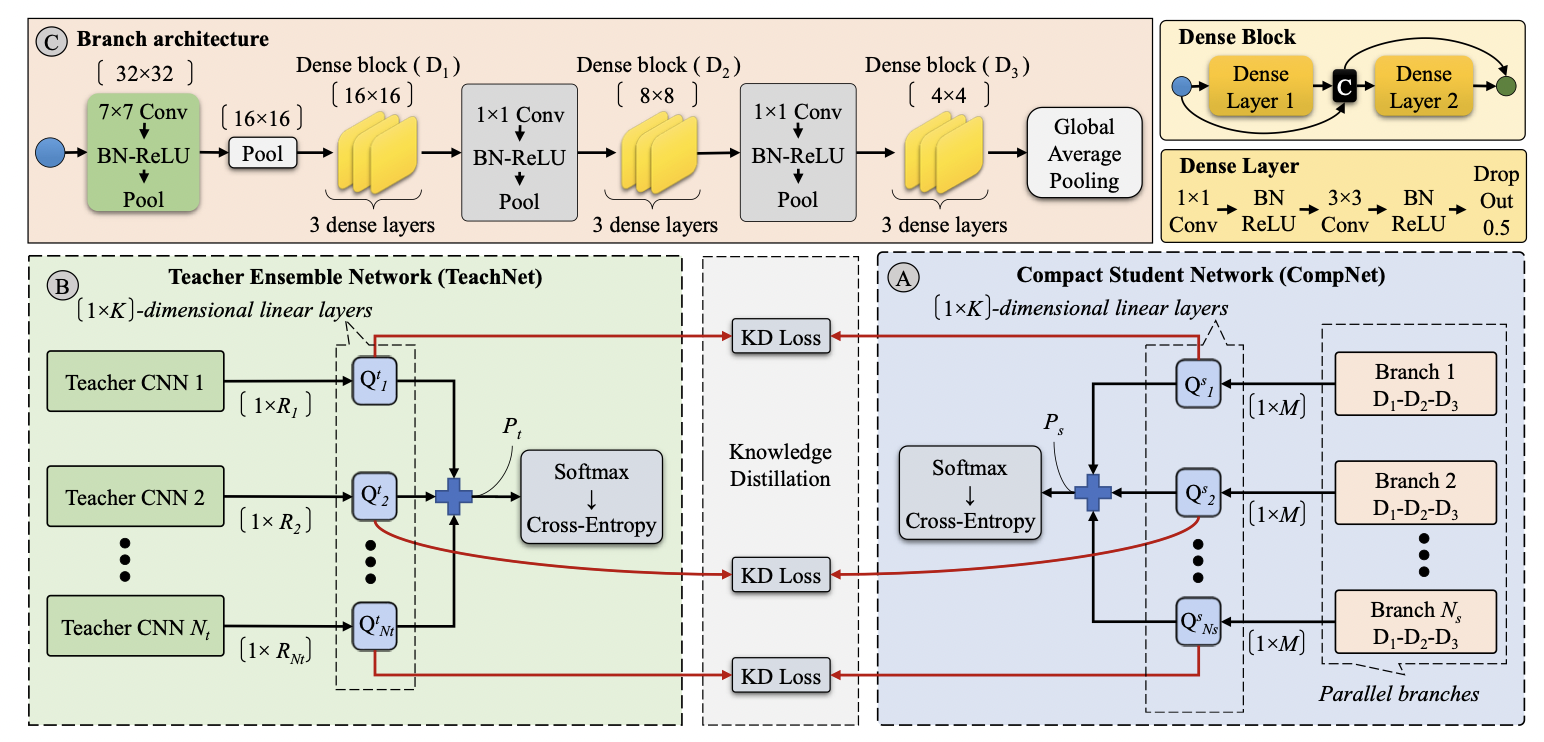
- 实验设置: teacher – ResNet14, ResNet20, ResNet26, ResNet32, ResNet44, ResNet56, and ResNet110; student – a CNN with dense connections, a medium capacity CNN with 6 dense layers (DenseNet6), a large capacity CNN with 12 dense layers (DenseNet12); 数据集: EKD, CIFAR-10, CIFAR-100.
- @article{asif2019ensemble, title={Ensemble knowledge distillation for learning improved and efficient networks}, author={Asif, Umar and Tang, Jianbin and Harrer, Stefan}, journal={ECAI}, year={2020} }
Stochasticity and Skip Connection Improve Knowledge Transfer. Lee, Kwangjin et al. ICLR 2020
- 问题: 部署多个教师网络有利于学生网络的学习, 但在一定程度上造成资源浪费.
- 方法: 利用单个教师网络生成多个教师网络 (加入add stochastic blocks和skip connections) 并训练学生网络, 在没有额外资源的情况下为学生网络提供足够的知识.
- 实验设置: 数据集 – CIFAR-100 和 tiny imagenet, 并将这种方法应用到KD, AT(attention tranfer), ML. 实验中涉及到的teacher有ResNet 32, ResNet 110, WRN 28-10, MobileNet, WRN 40-4; 涉及到的student有VGG 13, ResNet 20, ResNet 32, WRN 40-4.
- @INPROCEEDINGS{9287227, author={Nguyen, Luong Trung and Lee, Kwangjin and Shim, Byonghyo}, title={Stochasticity and Skip Connection Improve Knowledge Transfer}, booktitle={2020 28th European Signal Processing Conference (EUSIPCO)}, pages={1537-1541}, year={2021} }
Amalgamating Knowledge towards Comprehensive Classification. AAAI 2019
- 问题: 重用已经过训练的模型可以显著降低降低从头开始训练新模型的成本, 因为用于训练原始网络的注释通常不向公众公开.
- 方法: 使用multi-teacher KD的方法对多个模型进行合并, 得到轻量级的student模型. 方法分为两步: The feature amalgamation step – 将teacher的每一个中间层表示都合并, 得到student对应的中间层表示. 一种简单的方式是直接concat, 但会导致student变成teacher的4倍大小. 因此在concat多个teacher的中间层表示后经过一个auto-encoder, 压缩student’s feature的同时保留重要信息; The parameter learning step – 根据student相邻两层表示学习中间层参数.
- 损失函数由几部分组成: feature amalgamation – teacher的中间层表示concat之后经过$1\times 1$卷积得到压缩的表示, 再经过$1\times 1$卷积试图复原, 和concat的表示之差 (的模) 作为loss; parameter learning: student前一层表示 $F_a^{l-1}$ 经过中间层后的表示 $\hat{F}_a^l = conv(pool(activation(F_a^{l-1})))$ 和由teacher生成的下一层 $F_a^l$ 表示的差.
- 结构:
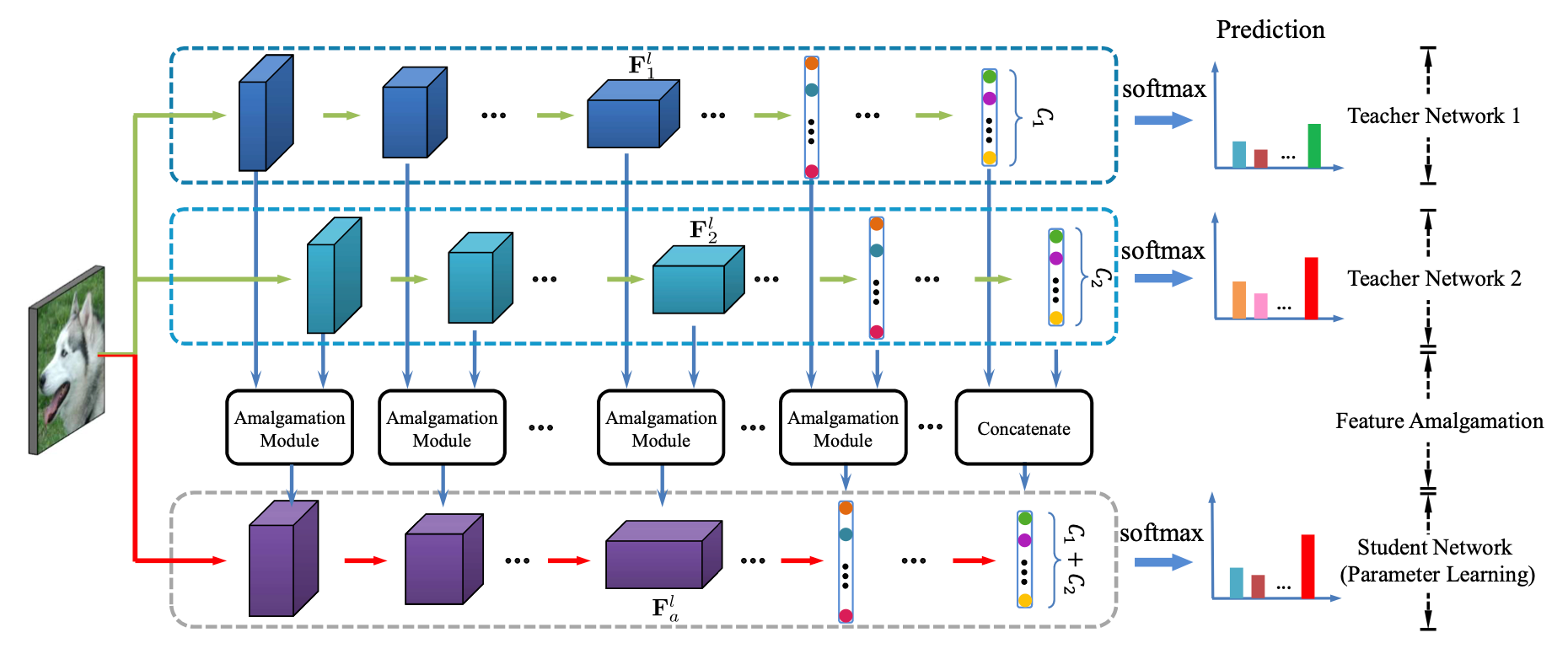
- 实验设置: 数据集 – CUB-200- 2011, Stanford Dogs, FGVC-Aircraft, Cars; teacher – AlexNet (在ImageNet上fine-tune)
- @inproceedings{shen2019amalgamating, title={Amalgamating knowledge towards comprehensive classification}, author={Shen, Chengchao and Wang, Xinchao and Song, Jie and Sun, Li and Song, Mingli}, booktitle={Proceedings of the AAAI Conference on Artificial Intelligence}, pages={3068–3075}, year={2019} }
Knowledge Amalgamation from Heterogeneous Networks by Common Feature Learning. IJCAI 2019
- 问题: 教师网络结构不一, 各自擅长解决不同的任务.
- 方法: student学习teacher经过转化的表示 (Common Feature Learning), 同时学习teacher输出的soft target.
- 结构:
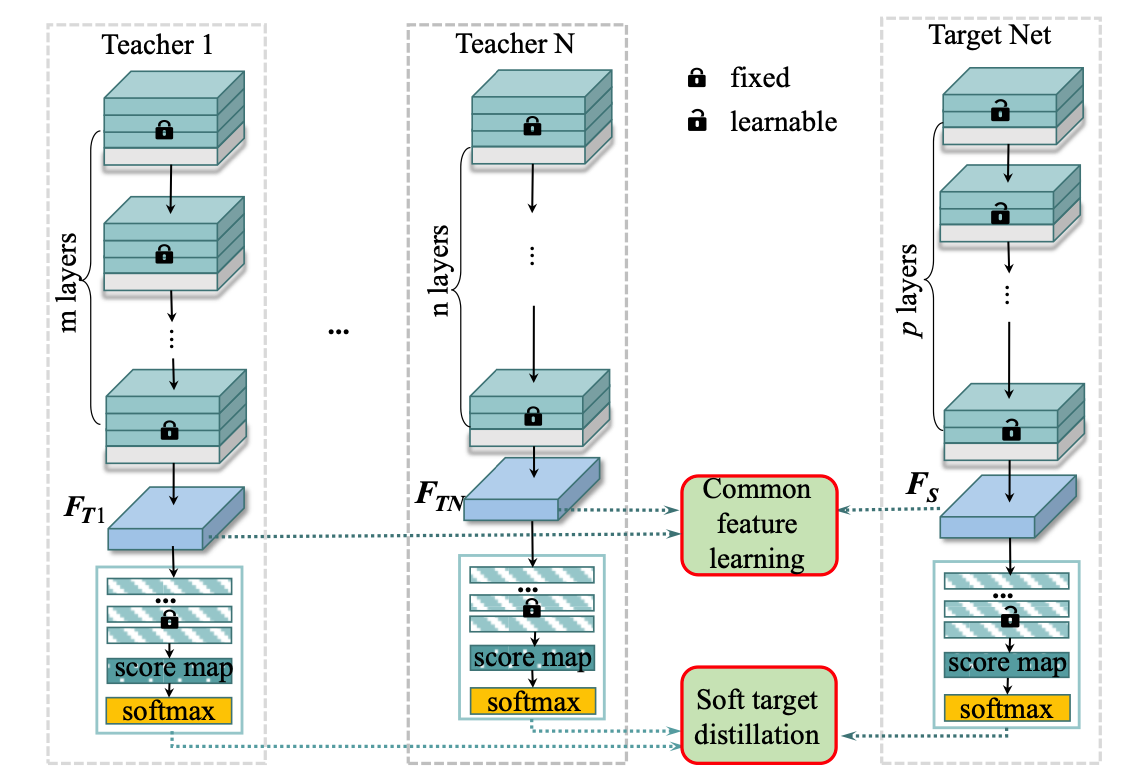
- 实验设置: networks: alexnet, vgg-16, resnet-18, resnet-34, resnet-50. datasets: (classification) Stanford Dog, Stanford Car, CUB200-2011, FGVC-Aircraft, Catech 101; (face) CASIA, MS-Celeb-1M, CFP-FP, LFW, AgeDB-30.
- @inproceedings{10.5555/3367243.3367468, author = {Luo Sihui, Wang Xinchao, Fang Gongfan, Hu Yao, Tao Dapeng, Song Mingli}, title = {Knowledge Amalgamation from Heterogeneous Networks by Common Feature Learning}, booktitle = {Proceedings of the 28th International Joint Conference on Artificial Intelligence}, pages = {3087–3093}, year = {2019} }
Customizing Student Networks From Heterogeneous Teachers via Adaptive Knowledge Amalgamation. CVPR 2019
https://openaccess.thecvf.com/content_ICCV_2019/papers/Shen_Customizing_Student_Networks_From_Heterogeneous_Teachers_via_Adaptive_Knowledge_Amalgamation_ICCV_2019_paper.pdf (这篇是多教师, 但主要针对的是从多任务的教师集合中进行选择性学习, 其中只需了解第三条, 针对的是问题中的“学生选择某个老师特征?”)
- 问题: 如何利用多个针对不同任务, 在不同数据集上优化的教师模型, 来训练可以定制的可以处理选择性任务的学生?
- 方法: 假设没有可用的人工注释,并且每个老师可能是单任务或多任务. 首先从共享相同子任务的异构教师(Source Net)中提取特定的知识(Component Net), 合并提取的知识以构建学生网络(Target Net). 为了促进训练,作者采用了选择性学习方案,对于每个未标记的样本,学生仅从具有最小预测歧义的教师那里自适应地学习.
- Selective Learning: $I(p^t(x_i)) = -\sum_ip^t(x_i)\log(p^t(x_i))$, 针对每个样本学生只学置信度最大的教师.
- 实验设置: 数据集: CelebFaces Attributes Dataset (CelebA), Stanford Dogs, FGVC-Aircraft, CUB-200-2011, Cars. Source net: resnet-18; component net and target net adopt resnet-18-like network architectures.
- @inproceedings{shen2019customizing, title={Customizing student networks from heterogeneous teachers via adaptive knowledge amalgamation}, author={Shen, Chengchao and Xue, Mengqi and Wang, Xinchao and Song, Jie and Sun, Li and Song, Mingli}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages={3504–3513}, year={2019} }
Collaboration by Competition: Self-coordinated Knowledge Amalgamation for Multi-talent Student Learning. ECCV 2020
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123510630.pdf (作者和"7"是同一个. 这篇文章主要针对多任务知识蒸馏, student的多个head针对不同任务, 但其中的Competi-Collaboration策略可以学习)
- 问题: 和"7"一样.
- 方法: 训练分为两步, 第一步整合teacher的多模态信息, 训练student的共享参数部分; 第二步用基于梯度的竞争-平衡策略, 训练student的multi-head部分, 每个部分针对不同的任务. 令$\Omega, \Theta_i, \Theta_j$表示student的共享参数部分 (encoder) 和两个针对特定任务的head参数, Competi-Collaboration策略迭代如下:
- Competition step: 固定student的共享参数部分, 最小化multi-head的输出和multi-teacher输出logits的差异.
- Collaborative step: 固定multi-head部分参数, 最小化$head_i, head_j$输出的logits和对应teacher的差, 以及student的encoder输出和teacher的encoder输出的差.
- 最后更新分配给$head_i, head_j$的权重 (计算loss时用到), 并归一化更新后的权重向量.
- 结构:
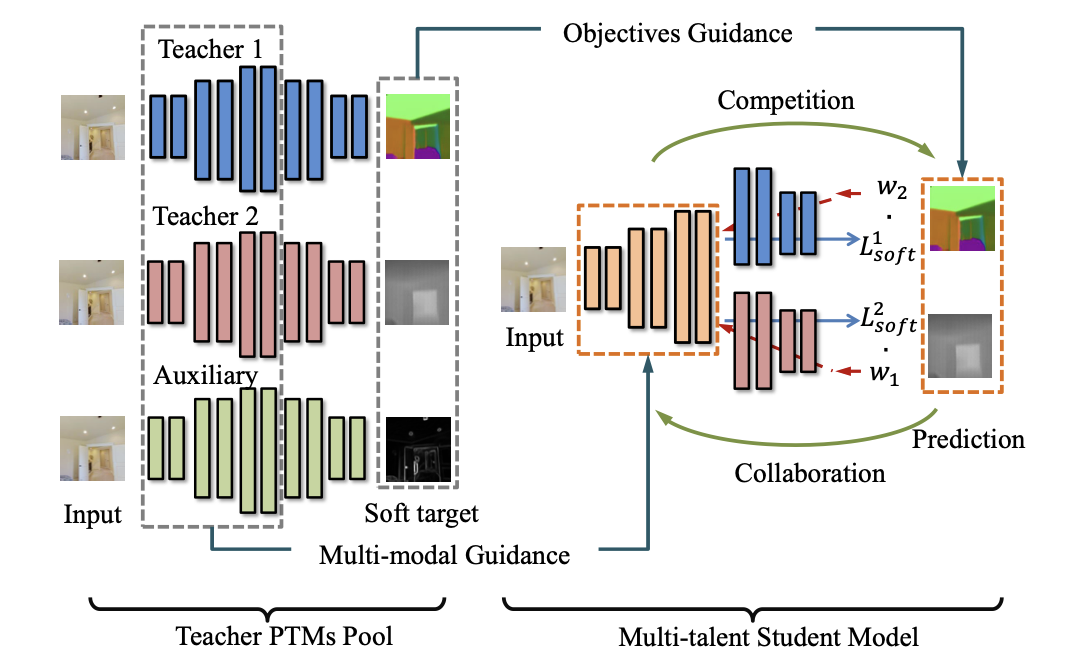
- 实验设置: 使用的数据集是Taskonomy dataset. teacher均使用taskonomy models, student的encoder使用ResNet-50加一个卷积层, decoder的结构根据具体任务各不相同.
- @InProceedings{10.1007/978-3-030-58539-6_38, author = {Luo Sihui, Pan Wenwen, Wang Xinchao, Wang Dazhou, Tang Haihong, Song Mingli}, title = {Collaboration by Competition: Self-coordinated Knowledge Amalgamation for Multi-talent Student Learning}, booktitle = {Computer Vision – ECCV 2020}, pages = {631–646}, year = {2020} }
Highlight Every Step: Knowledge Distillation via Collaborative Teaching
https://arxiv.org/pdf/1907.09643v1.pdf (这篇里用到的attention loss还行)
- 问题: 现有的知识蒸馏方法时常忽略训练过程中与训练结果有关的有价值的信息.
- 方法: 本文一共使用两个teacher, 一个是从头开始训练的 (scratch teacher), 指导student走能到达最终logits的最佳路径 (loss包含和groundtruth的交叉熵, 和student soft target的L2 loss); 另一个是已经预训练好的 (expert teacher), 引导学生专注于对任务更有用的关键区域 (会计算和student中间层表示的attention loss).
- 结构:
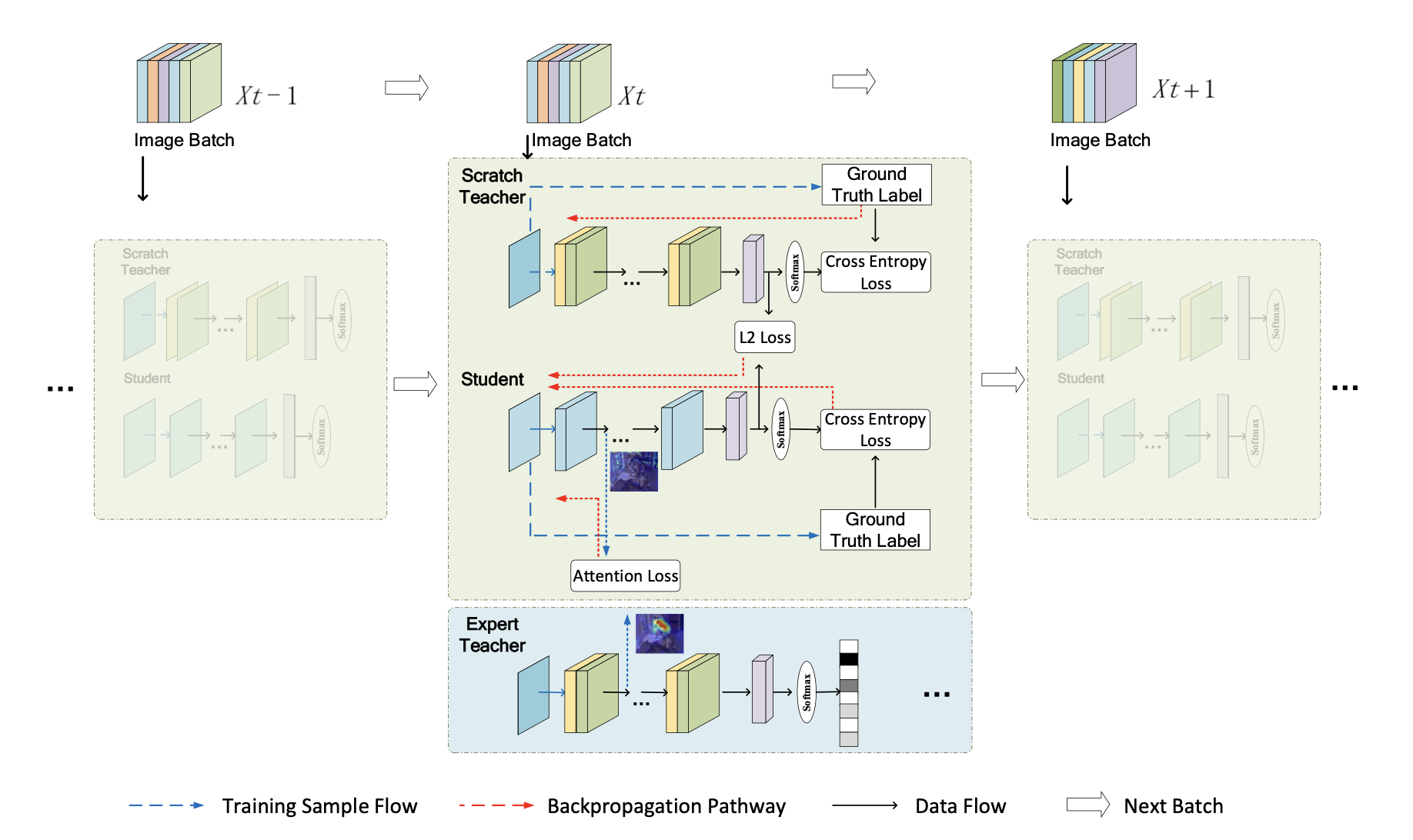
- 实验设置: 数据集采用CIFAR-10, CIFAR-100, SVHN和Tiny-ImageNet. teachers和student均使用Wide-ResNet, 其中teachers为WRN-40-1, student采用WRN-16-1.
- @ARTICLE{9151346, author={Zhao Haoran, Sun Xin, Dong Junyu, Chen Changrui, Dong Zihe}, title={Highlight Every Step: Knowledge Distillation via Collaborative Teaching}, journal={IEEE Transactions on Cybernetics}, pages={1-12}, year={2020} }
Knowledge flow: Improve upon your teachers. ICLR 2019
- 问题: 如今几乎对于所有给定的任务都可以使用现有的深度学习网络, 并且人们越来越不清楚在处理新任务时应从哪个网络开始, 或者选择哪个网络进行微调. 本文将"知识"从多个深度网络 (称为教师) 移动到一个新的深度网络模型 (称为学生). 教师和学生的结构可以任意不同, 他们也可以在具有不同输出空间的完全不同的任务上进行训练.
- 方法: 教师的中间层表示, 经过可训练的矩阵$Q$, 加权组成学生的中间层表示, 权重$w$也可学习.
- 实验设置: 主要是强化学习.
- @inproceedings{liu2018knowledge, title={Knowledge Flow: Improve Upon Your Teachers}, author={Iou-Jen Liu and Jian Peng and Alexander Schwing}, booktitle={International Conference on Learning Representations}, year={2019} }
Semi-Supervised Knowledge Amalgamation for Sequence Classification. AAAI 2021
https://www.aaai.org/AAAI21Papers/AAAI-1292.ThadajarassiriJ.pdf
- 问题: 每个教师在不同的训练集上训练, 导致他们对于未知的种类样本的输出是不可预测的, 并且和其他教师的输出无关. 因此在融合多教师的知识时, 一些教师有可能会给出很高置信度的错误分类.
- 方法: 包含两个部分, 一个是 Teacher Trust Learner (TTL), 在有标注训练集上训练对于给定输入样本, 每个教师的可信度有多高 $P(y_j\in\mathcal{Y}_k|X)$; 另一个是 Knowledge Amalgamator, 用于将多个教师给出的概率分布整合成在最终类别集合上的概率分布.
- 实验设置: Datasets: SyntheticControl (SYN), MelbournePedestrian (PED), Human Activity Recognition Using Smartphones (HAR), ElectricDevices (ELEC). Baselines: Original Teachers, SupLSTM, SelfTrain.
- @article{Sun2021CollaborativeTL, title={Collaborative Teacher-Student Learning via Multiple Knowledge Transfer}, author={Liyuan Sun, Jianping Gou, Lan Du, Dacheng Tao}, journal={ArXiv}, year={2021} }
Hydra: Preserving Ensemble Diversity for Model Distillation
- 普通multi-teacher KD对teacher的预测值取平均, 这样会丧失多teacher结果包含的不确定性信息, 本文将student拆分成body和多个head, 每个head对应一个teacher, 以保留多teacher输出的多样性
- 假设有M个teacher, 首先训练一个head直至其收敛至teacher的平均, 再添加其他M-1个head, M个head一起训练, 实验证明如果没有第一个head会很难收敛. 作者定义了一个模型不确定性, 由数据不确定性和总不确定性组成(我不理解为什么是这个顺序).
- 结构:

- 实验设置:
- 数据集: a spiral toy dataset(用于可视化并解释模型不确定性), MNIST(测试时用了它的测试集和Fashion-MNIST), CIFAR-10(测试时用了它的测试集, cyclic translated test set, 80 different corrupted test sets 和 SVHN).
- 模型: toy dataset - 两层MLP, 每层100个结点; MNIST - MLP; CIFAR-10 - ResNet-20 V1. 在回归问题中, 所有数据集均使用MLP.
- @article{DBLP:journals/corr/abs-2001-04694, author = {Linh Tran, Bastiaan S. Veeling, Kevin Roth, Jakub Swiatkowski, Joshua V. Dillon, Jasper Snoek, Stephan Mandt, Tim Salimans, Sebastian Nowozin, Rodolphe Jenatton}, title = {Hydra: Preserving Ensemble Diversity for Model Distillation}, journal = {CoRR}, year = {2020} }
Diversity Matters When Learning From Ensembles. NIPS 2021
https://papers.nips.cc/paper/2021/file/466473650870501e3600d9a1b4ee5d44-Paper.pdf
- 问题: 作者的假设是,一个蒸馏模型应该尽可能多地吸收集成模型内部的功能多样性, 而典型的蒸馏方法不能有效地传递这种多样性, 尤其是实现接近零训练误差的复杂模型.
- 方法: 首先证明了上述猜想, 随后作者提出了一种蒸馏扰动策略, 通过寻找使得集成成员输出不一致的输入来揭示多样性. 作者发现用这种扰动样本蒸馏出的模型确实表现出更好的多样性.
- 对于多个教师模型, 作者用ODS (输出多样性采样) 对输入样本添加扰动, 最大程度地提高集成的输出在所生成样本之间的多样性.
- 教师分别对添加扰动后的样本生成预测, 学生模型可以最大程度地学习教师模型的多样性.
- 设计的损失函数也很简单, CE + KD
- 结构:
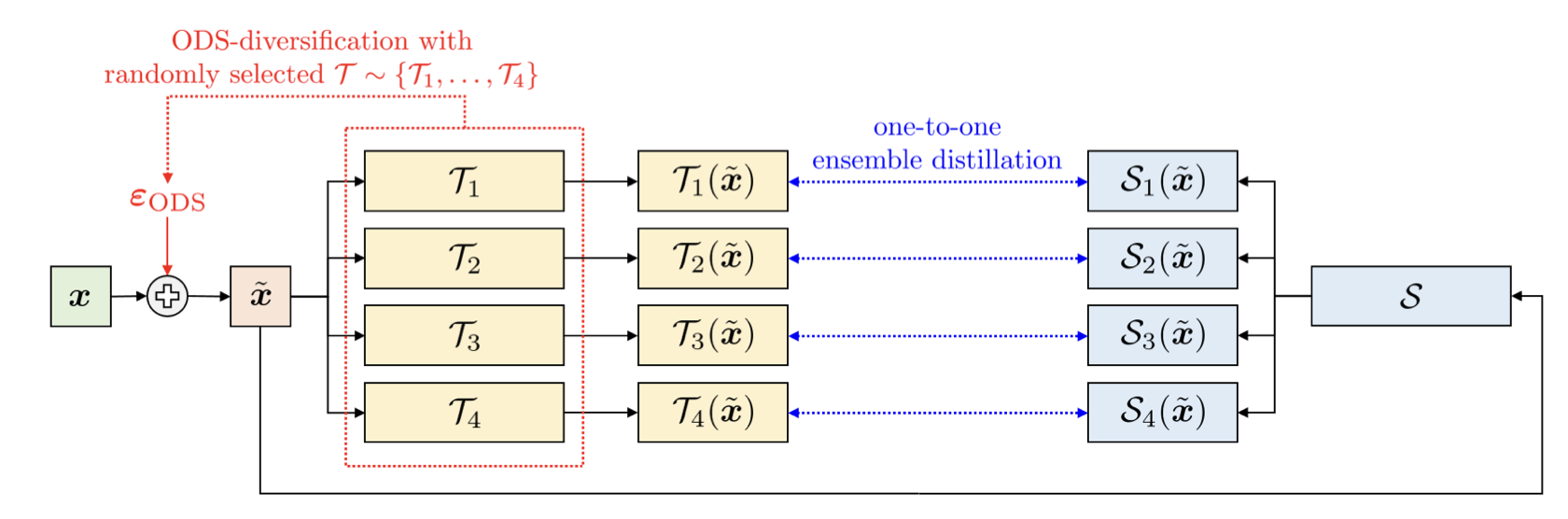
- 实验设置: 数据集: CIFAR-10, CIFAR-100, TinyImageNet. 在CIFAR-10上用的是ResNet-32, 在CIFAR-100, TinyImageNet上用的是WideResNet-28x10.
- @inproceedings{nam2021diversity, title={Diversity Matters When Learning From Ensembles}, author={Nam, Giung and Yoon, Jongmin and Lee, Yoonho and Lee, Juho}, booktitle={Thirty-Fifth Conference on Neural Information Processing Systems}, year={2021} }
Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective
- $L_{ce}=-y_k\log \hat{y}{k,1}^{s}, L{kd}=-\tau^2\sum_k\hat{y}{k,\tau}^t\log \hat{y}{k,\tau}^s$对两种期望错误率$\text{error}{ce},\text{error}{kd}$进行偏置-方差分解.
- $L_{kd}=L_{kd}-L_{ce}+L_{ce}$, 根据上一条, $L_{kd}-L_{ce}$导致方差减小, $L_{ce}$导致偏置减小.
- If a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective.
- 定义了 regularization sample: 定义两个量$a=\dfrac{\partial L_{ce}}{\partial z_i}, b=\dfrac{\partial(L_{kd}-L_{ce})}{\partial z_i}$, 对于一个样本, 当$b > a$时, 方差主导了优化的方向, 因此将这个样本定义为regularization sample.
- 实验表明, regularization sample的数量和训练的效果有一定的关系 (区别在于有没有 label smoothing的效果相差很大, 同时 regularization sample 的数量也相差很大; 但是$\tau$取不同值时训练效果和 regularization sample 的数量没有明显的关系)